C++ Under Dos
Harking back to the early days of computers, two people, working at Bell Labs had developed a programming language called 'C'. Compared to the languages in existence at that time, this language was a phenomenal leap ahead. No other language could match either the capability, or the flexibility, that C could offer. However, people soon learned that it was precisely this flexibility of C , that led to problems in debugging code, written in C. They yearned for something that contained all the features of C, along with a few additional features that would make code easier to debug. An example of what we are trying to say will be demonstrated in the following examples.
Consider the first example.
a1.c
main()
{
printf();
}
We have typed this program in BorlandC. As we may expect, we get no errors after compiling and linking. However, the output of this program appear to be some vague values.
a2.c
main()
{
printf(1000);
}
Consider the next C program that we have run. We realize that the compilation of this program, also, takes place without errors. When we run this program, we realize that the output, once again, is totally incomprehensible. All that we are trying to demonstrate are the minor lapses of C. Simple programs will compile without any problems. However, when we try to run them, we realize that the output we wish to obtain, simply did not materialize. For example, instead of printing 1000 when we run it, program a2.c just prints some junk. So, where was the problem? After all, if there is an error in our program, why isn't the compiler or the linker informing us about the problem? And if the program can't print what we want it to, why doesn't it just come back and tell us so. Aah! Haven't we just demonstrated that C, as we know it, is difficult to debug. No wonder that serious programmers in this world do not use C any longer.
One reason as to why we do not get errors in the C programs that we have just been working on, is due to the fact that the C compiler doesn't actually understand functions. And since it doesn't understand functions, it definitely cannot understand parameters that are passed to functions. Effectively, C just ignores all functions.
Let's go deeper into what happened in the programs that we just executed. We know that main() is always the first function to get called. Now, within the braces following main(), we give the name of the function along with the parameters we are going to pass to it. This statement is terminated, as usual, by a semicolon. The function we are calling in this program is printf( ). This function will be present beyond the braces that signal the end of the main() function. Any function that is outside main() doesn't really know of the parameters being passed to it. When the function is called, it will simply pick up the necessary parameters from the stack. Printf is a function that displays a string until it sees a 0, indicating the termination of the string
In the first program, our function printf will inquire about the location of the stack and start displaying whatever it finds there, until it encounters a 0. The second program will, however, specifically go to memory location 1000, and start printing whatever string is present from that location onwards.
Let us consider another program.
a3.c
main()
{
abc(10,20);
}
abc(int i,int j)
{
}
As usual, when we run this C program, we get no errors. As we have included no statement that will force our program to give us an output, no output is precisely what we are going to end up with. Now save this program with a .cpp extension. To be more accurate, save it as a3.cpp. A minor change, indeed, but one that is going to cause us innumerable headaches. Because on compilation of this program, we now end up with an error. Well, if C did not give us an error, why is it that the compilation of the same program completely stalled by the C++ compiler. Instead of tearing our heads in frustration, it would instead be safer to conclude that C++ just decided to act like the rest of the world. I've always maintained that the biggest problem with this world is that no one really trusts anyone else. I mean, why can't America just believe Saddam Hussein when he claims that Iraq has fully destroyed all it's nuclear weapon production plants? Why doesn't the Justice Department of the USA believe Microsoft when the latter claims that it isn't engaging in unfair trade practices? And why doesn't our C++ compiler just take our word? Why doesn't it just accept the fact that when we call function abc with two parameters, these two parameters that we are passing ,are exactly the same type as those that have been specified within our function abc?
When function abc is called, it will simply pick up the necessary parameters from the stack. As you can see, we have passed our function abc two integers. But the C++ compiler is adamant that we have to inform it, well in advance, as to precisely, what parameters we shall be passing to our function. Right now, it claims that it just doesn't know anything about the parameters of abc, which is why it simply terminates the compilation process midway, and gives us an error. This behaviour is very much unlike that of the C compiler, which doesn't really bother about what we pass to any function. To drive home this point, we make use of another C program.
a4.c
main()
{
abc(10);
}
abc(int i,int j)
{
}
Here, we only pass a single parameter to function abc which accepts two parameters. If we are expecting an error, we are definitely going to be dissapointed. We simply get a series of warnings. Have any of us ever really bothered about mere warnings from professors in college that we are falling behind in our studies. It was only when we flunked, that we looked back to see where we went wrong. The reason why C doesn't give us any errors is because of the same flexibility that we had earlier been talking about. Now save this program as a C++ program, and we shall realize that C++ isn't quite so lenient. We definitely get an error now.
At this point, let us go back to our previous C++ program a3.cpp, the one in which we passed two parameters to abc. A simple way to eliminate the error we got, would be simply to place the entire function abc, before main(). After all, the C++ compiler has simply to know all about function abc before it is called, and this is a simple way of fulfilling that criteria.
a5.cpp
abc(int i,int j)
{
}
main()
{
abc(10,20);
}
But what if we wish to have main() appear at the beginning of our program, to signify that main() is, after all, the function that is always called first. Or, what if we do not have the code of function abc, which means that there is no way by which we can place it before main(). In that case, before main(), we shall have to incorporate a statement that will give the compiler all the information it needs about our function abc. This declaration will include the name of the function as well as the type and number of parameters that are passed to the function. Such a statement is known as a function prototype. In actual fact, we also have to state the type of value, returned by the function. However the default is assumed to be an int. So, as long as the return value is an integer, we need not specify it.
a6.cpp
abc(int,int);
main()
{
abc(10,20);
}
abc(int i,int j)
{
}
Returning to our fourth C++ program, it will continue to give us errors, even if we resort to the two techniques discussed above. The compiler merely informs us that there are too few parameters in the call to function abc. The only way to eliminate this error is to actually have a function abc that accepts only one parameter, or pass two parameters to abc of datatypes as specified in the prototype. Here we have chosen the first option.
a4.cpp
abc(int);
main()
{
abc(10);
}
abc(int i)
{
}
Now consider the case when we have included something we use in almost each and every C program, namely printf(), within our own function abc.
a5.cpp
abc(int);
main()
{
abc(10);
}
abc(int i)
{
printf("hi");
}
On compiling this program, we get an unexpected error. At this point, we realize that printf is a essentially a function like any other. And like any other function we have to supply it's prototype, failing which, the C++ compiler will signal an error. Now the problem arises as to what the prototype of printf looks like, because, unlike function abc, we didn't write the code for the function printf(). We have no idea as to what the parameters accepted by printf() are. What we do know is that the people who wrote the function printf, placed it's prototype in a header file called stdio.h. All we have to do is include this header file in our program and the error vanishes.
a5.cpp
#include<stdio.h>
abc(int);
main()
{
abc(10);
}
abc(int i)
{
printf("hi");
}
All that we actually use in this entire header file is a single line of code that gives us the prototype of the function printf. Simply including the header file eliminates the necessity of bothering further about what parameters printf accepts, and so on. Instead, we could have just taken the single line that made up the prototype of printf, from the header file, and placed it at the beginning of our program. The program now executes without any further hassles, and says hi to us. Oh no! All that effort just for a simple hi ! Not worth it, if you ask me.
Consider the next program.
a6.cpp
main()
{
char *p;
p=100;
}
Compiling this program as a simple C program definitely gives us no errors. But merely giving it a .cpp extention, however will give rise to an error informing us that the conversion from int to char* is not possible. Once again, the strict error checking capabilities of C++ are evident to one and all. We cannot pass an integer in place of a pointer, or a long in place of a character, directly. In such cases, we have to take a more round-about route. A route known as casting. The term, itself might put you off, but actually, it simply means that we are ensuring that the terms to the right of an equal-to sign, ie '=', match the terms to the left of the same sign. All that we really have to is to place (char *), that is, the type of parameter p, within brackets, before anything we want to cast it to. This will, in no way, change any value to the right of the equal to sign. We can safely assure you that the value, 100, is not going to change to 101, or anything else, after the casting has been performed. Placing the cast just ensures that our program compiles without further problems.
C++ has extremely strict rules to ensure that what is on the type of variable to the right of the equal-to sign is the same as what's on it's right. Casting is a way that allows us to break these rules, enabling us to assign one variable type to a totally dissimilar variable type.
a6.cpp
main()
{
char *p;
p=(char *)100;
}
We now go one stage further. We had earlier stated that C didn't really know much about functions, and even less about their parameters. Also, that C++ treats functions in a manner totally different from that of C. Lets go back to a C program , which has one function that accepts two parameters. We now only compile this file without building it. At the end of this process, we get an Obj file. We use the 'type' command to print this file out, by saying 'type a7.obj'. If we now search through the maze of incomprehensible symbols printed out, we shall see the term _abc. Repeat the same process with a8.c, in which function abc has only one parameter. When we now compile and type the obj file we still see function abc in exactly the same form as in the earlier program, namely _abc.
a7.c a8.c
main() main()
{ {
abc(10,20); abc(10);
} }
a7.cpp a8.cpp
abc(int,int); abc(int);
main() main()
{ {
abc(10,20); abc(10);
} }
We now take a look at the C++ equivalents of the same programs. We compile a7.cpp and print it's Obj file. We now notice a slight change in the manner in which function abc appears. It appears as @abc$qii. So maybe, this is the way that C++ displays functions. Compile a8.cpp, and view the obj file. Surprise!Surprise! Our function is no longer @abc$qii, but simply @abc$qi. We thus observe that the single 'i' at the end of the function name actually refers to the fact that the function abc has an integer as a parameter. We now realize that the C++ has treated the same function in a different manner. The name of the function in the Obj file has been totally changed, after we have changed it's parameters. You may think that the merely the addition of a single character is no great deal, but try sending us E-Mail at vmukhii@giasbm01.vsnl.net.in instead of vmukhi@giasbm01.vsnl.net.in. It will definitely not reach us. The mere addition of an extra 'i', results in the name being totally changed. This property of changing the function name totally based on what the parameters are, is known as Name Mangling. Some people also call this same property, function overloading, where we can have more than one function of the same name, within a program, as long as the parameters being passed to it are not the same. Alternately, we could also call this property polymorphism. However, if you are from Microsoft or you are a great fan of the Bill Gates, you may call this the property of Decorative Names.
We could also test the same function by now passing two characters instead of integers. Once again the name of the function in the obj file changes, this time to @abc$qzczc, where 'zc' denotes that the parameter is a character. Similarly, having one character and one integer as parameters of abc result in the name being changed to @abc$qzci. We now conclude that C++ treats functions with the same function name, differently, if their parameters are not the same. We could take advantage of this feature of C++, to perform different tasks based on the number of parameters passed to a number of functions, all having the same name.
Consider the next program. If we save this program as C program, we shall get compilation error that say 'type mismatch in redeclaration of abc','extra parameter in call to abc' and so on. This is because C obviously cannot distinguish between two functions of the same name, having different parameters. C++ on the other hand, has no such problems, and the program executes with absolutely no hassles.
a9.cpp
#include<stdio.h>
abc(int);
abc(int, int);
main()
{
abc(10,20);
abc(100);
}
abc(int i,int j)
{
printf("%d..%d\n",i,j);
}
abc(int k)
{
printf("%d..\n",k);
}
Before we go on to the next topic, let us look at a very prominent feature of the C programming language, namely structures. It's almost impossible to describe just how useful, structures proved to be to us. Suppose we had a very rich family called the Ford family, that had six members: Tom, Dick, Harry, Liz, Mary and Jane. Let us assume that we need to know the monthly income of each and every member of the family. Which could mean that we are either from the IRS/Income Tax Department, or just common criminals. Either way, we would be very interested in keeping tabs on everyone's income. To do so, we could make use of a computer program. Since all these people are from one family, wouldn't it be convenient for us to be able to group them all under one heading. After all, their's might not be the only family we wish to loot. ( Oh boy! Did we just give ourselves away?) Suppose we were collecting information about a hundred people in town, maybe, we could have just created variables to access each of these hundred people, but it would definitely be easier to just group them according to the family they belonged to. In doing so, we also would be avoiding the possibility of a huge mess, later on, when we may be tracking an even larger number of people. To serve precisely this need, we make use of structures. We could create a structure that contained the required information about all the members of this family, and name this structure Ford. We could now make use of the 'Ford' structure to update ourselves about the income of any member of this family.
What we are trying to say is that structures make our lives easier. But first, let us look at an example of a structure.
sc1.cpp
#include<stdio.h>
struct zzz
{
int i,j;
};
main()
{
struct zzz a;
printf("Size = %d\n",sizeof(a));
printf("Location= %p\n",&a);
}
Here, zzz is a structure tag with two members, i and j. Within main( ), we have the statement 'struct zzz a;' By this statement, we are saying that 'a' is now a structure that looks like zzz. We can print the size of this structure as well as it's location in memory.
We may now access any variable within zzz through 'a'. This is shown in the next program.
Since variables i and j now belong to the family of 'a', to access them, we say a.i and a.j. Since we are using the C++ programming language, we may even avoid the use of the keyword struct, while declaring 'a'.
The statement 'zzz a;' accomplishes the same thing.
sc2.cpp
#include<stdio.h>
struct zzz
{
int i,j;
};
main()
{
zzz a;
printf("Address of a is %p\n",&a);
printf("Variables values are %d ..%d ", a.i,a.j);
printf("Variables addr are %p and %p ", &a.i,&a.j);
}
OUTPUT:
Address of a is 09F8:0FFC Variables values are 294..857 Variables addr are 09F8:0FFC and 09F8:0FFE
As the variables i and j have not been initialized, the values that are displayed may be just anything. But the addresses of one of the variables is the same as the address of structure in memory. Of course, we can also declare another structure, 'b', that looks like zzz. This structure would be allocated a totally different memory location, and can also access variables in a manner similar to that of 'a'. The address of 'b' will also be the same that of ' b.i '.
sc3.cpp
#include<stdio.h>
struct zzz
{
int i,j;
};
main()
{
zzz a;
printf("Address of a is %p\n",&a);
a.i=10; a.j=20;
printf("Variables %d...%d\n",a.i,a.j);
printf("Variables addr are %p and %p ", &a.i,&a.j);
zzz b;
printf("Address of b is %p\n",&b);
b.i=100; b.j=200;
printf("Variables %d...%d\n",b.i,b.j);
printf("Variables addr are %p and %p ", &b.i,&b.j);
}
OUTPUT:
Address of a is 1BF4:0FFC Variables 10...20 Variables addr are 1BF4:0FFC and 1BF4:0FFE Address of b is 1BF4:0FF8 Variables 100...200 Variables addr are 1BF4:0FF8 and 1BF4:0FFA
Now, we shall do something that we were not able to do while using 'C'. We shall actually incorporate a function within our structure zzz. Now, maybe, you might wonder as to why we need functions within our structures. To answer that question, lets just say that the use of functions within structures increases their utility a hundred fold. Now, even functions can be called in a manner similar to that of variables. However, while each variable within a structure may only be able to inform us about their value at that instant, a function could perform a variety of tasks , all at one go.
By that, we mean that we now do not have to first obtain the values of each variable from main(), before performing any desired task with these variables. Everything can now be done within the structure itself . For example, if we go back to our old Ford structure, we could now have a function that will display a list of only those people whose income exceeds $10,000 per month. In other words, we could now do some intelligent processing work within our structure.
sc4.cpp
#include<stdio.h>
struct zzz
{
int i,j;
abc()
{
printf("abc\n");
}
};
main()
{
zzz a;
printf("Addr =%p\n",&a);
printf("Variables %d...%d\n",a.i,a.j);
a.abc();
}
To further demonstrate what we can do with functions within structures, we have placed a single function print, within zzz, that we shall access from both the structures, a as well as b.
sc5.cpp
#include<stdio.h>
struct zzz
{
int i,j;
void print()
{
printf("%d...%d\n",i,j);
}
};
main()
{
zzz a;
a.i=10;a.j=20;
a.print();
zzz b;
b.i=100;b.j=200;
b.print();
a.print();
}
Now, when function print is called, it accepts only those values of members of that particular structure from where it has been called. So, obviously, when we call print from the structure b, it will only display the values that have been assigned to the variables of that structure, ie 100 and 200. The values of the variables that have been assigned by structure 'a', remain unchanged, at 10 and 20. This can be seen from the output of the last print statement.
Until this point, we have freely incorporated functions within structures. However, when we think of the term structure , we tend to refer to the conventional C definition of a structure, which refers to merely a group of variables. So, whenever we have to have functions within a structure in C++, we do not call it a structure any longer. We now give such a structure a new name, Class. To differentiate between all variables, structures and classes, we may use the following distinguishing points. A variable has one value at any point in time, while a structure is merely a collection of variables. A class, on the other hand, is a structure tag that contains code or functions within it.
We shall now replace the word structure by the word class, in our next program.
sc6.cpp
#include<stdio.h>
class zzz
{
int i;
int j;
void print()
{
printf("%d...%d\n",i,j);
}
};
main()
{
zzz a;
a.i=10;a.j=20;
a.print();
}
When we compile this program, however, we end up with quite a few errors. So, was our previous statement about replacing the word struct by the word class, wrong? Well, not quite. While we can make use of the word class, C++ now treats the variables and the functions within our renamed structure, in a slightly different manner. Earlier, we could access a member of the structure without any problems. However, the members of a class have specifically to be declared accessible to all, so that they can be used outside the class. This can be achieved by the statement, public :
sc7.cpp
#include<stdio.h>
class zzz
{
int i;
public:
int j;
void print()
{
printf("%d...%d\n",i,j);
}
};
main()
{
zzz a;
a.i=10;
a.j=20;
a.print();
}
When we now compile our program, we just get a single error to signify that the variable i, is not accessible to anyone. However, we may now access the variable j, or the function print(), without any problems. To remove all the errors during compilation, we simply place the 'public :' , before declaring any variables or functions that have to be accessed from outside the class.
We had earlier mentioned that 'a' was a structure that looked like the structure tag zzz. But, now that zzz is called a class, shouldn't it be appropriate to rename 'a', as well? So we no longer call 'a', a structure, but instead, refer to it as an object of class zzz. We could also describe 'a' as being an instance, or an occurance, of class zzz. Similar to structures, we can create several objects of the same class. Now consider the next program.
inh1.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
void abc()
{
printf("In abc zzz");
}
void print()
{
printf("%d...%d\n",i,j);
}
};
main()
{
zzz a;
a.i=10;a.j=20;
a.print();
a.abc();
yyy b;
}
When we compile the above program, we definitely get errors. After all, we are trying to create an object 'b' that looks like yyy, which in turn, does not exist. We first have to specifically make the statement 'class yyy{};', which will easily convince the compiler that yyy is a class. Only then can we create an object that looks like yyy.
inh2.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
void abc()
{
printf("In abc zzz");
}
void print()
{
printf("%d...%d\n",i,j);
}
};
class yyy
{
};
main()
{
zzz a;
a.i=10;a.j=20;
a.print();
a.abc();
yyy b;
b.i=100;
}
The original error that we had, disappears. Which means that object b has been created. We had, however added a single line of code, wherein, we attempted to assign some value to a variable i, using the object 'b'. We now encounter a new error saying that the variable i, is not a member of class yyy. This is, but obvious, as class yyy does not contain any code right now. This variable i, however, is a member of class zzz. So, is it possible for 'b' to ever be able to access variable i, even if it belongs to another class? To find out, read ahead.
inh3.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
void abc()
{
printf("In abc zzz");
}
void print()
{
printf("%d...%d\n",i,j);
}
};
class yyy:public zzz
{
};
main()
{
zzz a;
a.i=10;a.j=20;
a.print();
a.abc();
yyy b;
b.i=100;
b.j=200;
b.print();
}
When we compile this program, we might be surprised to get absolutely no errors. As far as we can see, class yyy still contains no code. But actually, this is not the case. When we use the statement 'class yyy : public zzz ', we are essentially deriving class yyy from class zzz. In other words, whatever code present within class zzz, is taken and pasted into class yyy. Class yyy may freely make use of a variable or function from any class, as long as we use :public, along with the name of that class. Once again, just as in structures, changing the values assigned to variables of object 'b', does not have any effect on those of object 'a'.
inh4.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
void abc()
{
printf("In abc zzz\n");
}
void print()
{
printf("from print %d...%d\n",i,j);
}
};
class yyy:public zzz
{
public:
void pqr()
{
printf("in pqr yyy\n");
}
};
main()
{
zzz a;
a.i=10;a.j=20;
a.print();
a.abc();
yyy b;
b.i=100;
b.j=200;
b.print();
b.abc();
b.pqr();
a.print();
}
OUTPUT:
from print10...20 In abc zzz from print100...200 In abc zzz in pqr yyy from print10...20
Here, we have shown that object 'b' can call any function from the class zzz, as well as all the functions in class yyy. Class zzz is called the base class, while class yyy is called the derived class. In this program, we have proved that the derived class now contains all it's own functions, as well as the functions, it obtained from the base class. But let's divert our attention back to the Ford family, in particular, Tom Ford. Being the eldest of the siblings, he inherited the Ford family fortune on the sad demise of their parents. But, since the lad had been working for quite sometime, he also had savings of his own. In other words, his total worth was now greater than that of his parents. Any derived class behaves in a manner similar to that of Tom Ford. In size, it is now much larger that the base class.
The code of the function print(),is automatically inserted into yyy, since yyy is derived from class zzz. It is the same case with the variables i and j. Because of this, we may safely initialize these variables from 'b', and rest, assured that only the values of b.i and b.j, and none other will be displayed, when the statement b.print() is executed.
While the derived class can use any function present in the base class, the same is not true in the reverse case. It is simply not possible for us to have the statement ' a.pqr(); ', in this particular program. Now let us see what happens when we have a function with the same name in the base class, as well as the derived class.
inh5.cpp
#include<stdio.h>
class zzz
{
public:
void abc()
{
printf("In abc zzz \n");
}
};
class yyy:public zzz
{
public:
void pqr()
{
printf("in pqr yyy \n");
}
void abc()
{
printf("In abc yyy \n");
}
};
main()
{
zzz a;
yyy b;
a.abc();
b.pqr();
b.abc();
}
The output of this program is :
In abc zzz In pqr yyy In abc yyy
In other words, if the same function is present in both, the base and the derived class, and we are calling this function from the object of the derived class, the function from the derived class is called. In this case, obviously, abc will be called from class yyy, and not from class zzz. Only when abc is not present in class yyy, will it be called from class zzz. So, what is the use of inheritance ? We have a number of development tools that are written using C++. The designers of these tools give us a variety of classes to ease our load. These classes contain complex code that automatically performs many useful tasks. We may derive our own class from such classes, and make use of all their code. In the case of complex tasks that are performed repetitively, this method goes a long way in reducing the amount of code that we have to write. We always derive a class from the original class, because we do not, under any circumstances, want to change the original class. We are, however, free to override any function present in the original class, simply by placing the name of that function within our class, and writing our own code within it.
Now let's look at how memory is allocated in C++, to objects. One unique feature of C++, is that anything and everything is either a class, or an object, which in turn is nothing but an instance of a class. When we have to create an instance of class zzz, don't we just use the statement ' zzz a; ' ?
When this statement is executed, an object 'a' is created that looks like class zzz. Now, look at the statement we use, when we want to have an integer, called i, in our program. We simply say ' int i; '.
Now, isn't this very similar to the statement in which we create an object that looked like class zzz ?
So, we can safely come to the conclusion that 'int' is actually a class in C++, and the statement ' int i; ' actually leads to the creation of an object of that class. This object is also allocated some memory.
Similarly, all other variable types are also classes, in reality.
Consider the statement shown below.
int *j;
Does this statement also lead to the creation of an object? Actually, no. All that we have done is declare that j is a pointer to class ' int '. An object will only be created if we add the code
' j = new int; ' , after the above statement. It's now time to take a look at our next program.
cc1.cpp
#include<stdio.h>
main()
{
int *j;
j=new int;
printf("addr %p\n",j);
j=new int;
printf("addr %p",j);
}
We are creating two objects in this program. Both these objects are not only called by the same name 'j', but they are also instances of the same class, int. In case you expected this program to show errors, you will definitely be disappointed. We are permitted to create two instances of a class in a program, that have the same name. What the keyword 'new' does, is first find out the size of the class, in this case, class ' int '. It then allocates enough memory for this class by calling malloc. After all this only, is an object called j created. If new is called twice, memory will have to be allocated twice.
We now turn our attention to doing something similar, but with a class of our own.
cc2.cpp
#include<stdio.h>
class zzz
{
public:
void abc()
{
printf("hi");
}
};
main()
{
zzz *a;
a=new zzz;
printf("%p \n",a);
a=new zzz;
printf("%p \n",a);
}
Here, 'a' is a pointer to class zzz. Other than that, the execution of the program proceeds in exactly the same way as the previous program. All this only proves that ' int ' is actually a class, and is treated exactly the same way, as our own class is treated. Now consider the case where we have a class containing a function of the same name, as shown in the next program.
cc3.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
printf("In function zzz within class zzz\n");
}
print()
{
printf("i=%d....j=%d\n",i,j);
}
};
main()
{
zzz a;
a.print();
}
We certainly expect this program to call the function print(), on execution. What we hadn't bargained for is an output that appears as shown below.
In function zzz within class zzz
i=635...j=483
The function print may output any vague value, as we haven't initialized variables i and j. What amazes us, is the fact that function zzz has also been called. Nowhere in the above program have we made the statement' a.zzz(); '. If we haven't explicitly called a function from the class, how has function zzz been called ?
And can we call this function in the normal manner, by just saying ' a.zzz(); ' ?
cc4.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
printf("In function zzz within class zzz\n");
}
print()
{
printf("i=%d....j=%d\n",i,j);
}
};
main()
{
zzz a;
a.zzz();
}
To our amazement, we get an error saying that zzz is not a member of class zzz. Can't the C++ compiler see that this function is present within class zzz. In fact, in the previous program itself, the very same function had been called. This is crazy! When we actually try to call this function, we just cannot call it, but when we don't call it, it get's called automatically!
Aah! Another unique feature of C++. As soon as we create the object of a class, a function within the class, having the same name as that of the class, will automatically be called. However, C++ doesn't take it very kindly, if we try to call this function explicitly. As far as it is concerned, this is an act of aggression, and an invasion of it's own turf. Permission to call a function that has the same name as that of the class it belongs to is denied to one and all. But, perhaps after relenting a bit, C++ gives us this function anyway, even if we are not really interested in calling it. As soon as the object is created, this function get called automatically.
Such a function is known as a constructor.
In most other respects, a constructor behaves like other functions in C++, and exhibits overloading. This will be demonstrated in the next program.
cc5.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
printf("In constructor with no parameters\n");
}
zzz(int)
{
printf("In constructor with one parameter\n");
}
};
main()
{
zzz a;
zzz b(10);
}
OUTPUT:
In constructor with no parameters In constructor with one parameter
The two constructors get called, as expected. Thus, we can even have constructors with any number of parameters. In C++, which is a language that exhibits very strong type checking, correct return values are of utmost importance. So what are the return values of a constructor ? Let us experiment by placing various return values before the constructor, starting with ' int '.
cc6.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
int zzz()
{
printf("In constructor with no parameters\n");
}
};
main()
{
zzz a;
}
Error ! Error ! 'Constructor can't have a return type specification' , the C++ compiler informs us. What if we make the return value of this function, a ' void '. After all, the constructor does appear to return no value. No luck there, either. Same error. Basically, a function is called from main() conventionally, by giving the name of the function, and terminating the statement with a semicolon. It is this very statement, that accepts a return value. A constructor, however, is called automatically whenever an object is created. Which means that there is nothing that can accept a return value. That is why we get an error.
If we look back, we shall realize that, in our earlier programs, we didn't have a function of the same name as the class. So, we wonder, what exactly used to happen in those programs? Was an object being created, without a constructor being called ? That would be a violation of the rules of C++. Which is why, when we create an object, C++, on it's own, inserts a constructor without any parameters and containing no code, into the class. If that is the case, then maybe, we can just delete the constructor without parameters. After all, who doesn't like to accept anything given free ?
cc7.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int)
{
printf("In constructor with one parameter\n");
}
};
main()
{
zzz a;
zzz b(10);
}
Unfortunately, C++ has come to the conclusion that, since we are rich enough to afford our own constructor with one parameter, we do not need it's charity. It is, now, not going to insert a free constructor without parameters. So, it now gives us an error saying that it cannot find a match for this constructor. We are therefore forced to insert this constructor, ourselves.
In an earlier program, our class contained variables that weren't initialized. Let us now initialize these variables, and print their values.
cc8.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
i=10;
j=20;
zzz()
{
printf("In Constructor\n");
}
print()
{
printf("i=%d....j=%d\n",i,j);
}
};
main()
{
zzz a;
a.print();
}
To our great horror, we get errors like 'Type name expected'
'Multiple declaration for i' 'Cannot initialize a class member here'
Of course, these errors are repeated for the second variable. The third error causes to ponder for a moment. If we cannot initialize these variables here, then maybe we should just try elsewhere. Such as, within the constructor.
cc9.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
i=10;
j=20;
printf("In Constructor\n");
}
print()
{
printf("i=%d....j=%d\n",i,j);
}
};
main()
{
zzz a;
a.print();
}
OUTPUT:
In Constructor i=10....j=20
This program, more than any other, brings out the necessity of having constructors. C++ does not allow us to directly initialize a variable in a class, anywhere else. We have to initialize them only within a constructor.
th1.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
printf("In constructor \n");
}
};
main()
{
zzz *a;
a=new zzz;
printf(" Address of a..%p",a);
}
In the above program, we have a class with a single constructor. It is only when the 'new' operator works on the class, that an object of the class is created. Along with the object being created, 'new' performs a few more tasks. It makes sure that the variables are placed in one section of memory, while the functions are placed in a different section. At the instant of the creation of the object, the constructor gets called automatically. Here, we have printed the address of where this object is placed in memory. Now, the object should be placed in memory, at exactly the same location, as one of the variables.
In the next stage, we have created one more object 'b'. We have also initialized the variables i and j, in the constructor. The last change we made, was to incorporate a function called print within our class, to display these variables.
th2.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
i=0;
j=0;
printf("In constructor \n");
}
void print()
{
printf("i=%d....j=%d\n",i,j);
}
};
main()
{
zzz *a;
a=new zzz;
printf("%p...address of a\n",a);
a->print();
zzz *b;
b=new zzz;
printf("%p...address of b\n",b);
b->print();
}
Nothing much different happens in this program. The function, print, displays the values of i and j, which are 0, at all times. Of course, the objects, 'a' and 'b' will be assigned different memory addresses.
Let us now have a function that will change these values of i and j.
th3.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
i=0;
j=0;
printf("In constructor \n");
}
void print()
{
printf("i=%d....j=%d\n",i,j);
}
void change(int x, int y)
{
i=x; j=y;
}
};
main()
{
zzz *a;
a=new zzz;
a->change(10,20);
zzz *b;
b=new zzz;
b->change(1,2);
a->print();
b->print();
}
The function, change(), will assign whatever values that have been passed to it to the variables i and j. Thus in our output, we shall see i=10..j=20, followed by i=1..j=2. These values have been displayed by the function, print(). But let's take a deeper look into what's really going on in this program. When any function, irrespective of whether it is in C or C++, gets called, it doesn't have the faintest idea as to who is calling it. All that the function does, is to take a look at the stack, and pick up the required parameters. If that is the case, then how does print() manage to display only the values that belong to the particular object that calls it?
We now do something that seems to be totally irrational. Within the constructor, we attempt to display the address of something called 'this'. We also display the addresses of both the objects.
th4.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
i=0; j=0;
printf("In constructor this=%p \n",this);
}
void print()
{
printf("i=%d....j=%d\n",i,j);
}
void change(int x, int y)
{
i=x; j=y;
}
};
main()
{
zzz *a;
a=new zzz;
printf("address of a %p\n",a);
a->change(10,20);
a->print();
zzz *b;
b=new zzz;
printf("address of b %p\n",b);
b->change(1,2);
b->print();
}
We do not get any errors when we compile our program. That could only mean one thing. A variable called 'this' is actually exists. But, where have we created the variable in question?
As far as our program is concerned, we have only four options as to where we can create variables. We can do it within the round brackets following the name of the function, or within the curly braces that follow. We may also create the variable just after public: within the class, or declare it globally. It is quite evident that we have not used any of these options while creating the variable 'this'.
When we write the word 'this', to our surprise the colour of the word changes. A clear indication that the term 'this', is infact a reserved word that actually has some meaning in C++. A bigger surprise, however, awaits us. Let us look at the output of this program.
In constructor this=0B4D:0004 address of a 0B4D:0004 i=10....j=20 In constructor this=0B4E:0004 address of b 0B4E:0004 i=1....j=2
We notice that each time an object gets created, and the corresponding constructor gets called, the address of the object is exactly the same as that of the term 'this'. So what is 'this' ? Haven't we ever told you what a great language C++ is ? It's about time that we did. C++ creates a pointer to the current class and places it in the constructor, as the first parameter of the constructor. A real freebee. The designers of C++ however, were probably running short of names. So they named the pointer to the current class 'this'. The constructor of class zzz now looks like, internally.
zzz( zzz *this)
{
this->i=0; this->j=0;
printf("In constructor this=%p \n",this);
}
C++ can now easily make use of the pointer to access the variables passed by the object. While we cannot physically place ' zzz *this ' as a parameter, nothing prevents us from using this->i and this->j in place of variables i and j.
th5.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
this->i=0;
this->j=0;
printf("In constructor this=%p \n",this);
}
void print()
{
printf("i=%d....j=%d\n",this->i,this->j);
}
void change(int x, int y)
{
i=x; j=y;
}
};
main()
{
zzz *a;
a=new zzz;
printf("address of a %p\n",a);
a->change(10,20);
zzz *b;
b=new zzz;
printf("address of b %p\n",b);
b->change(1,2);
a->print();
b->print();
}
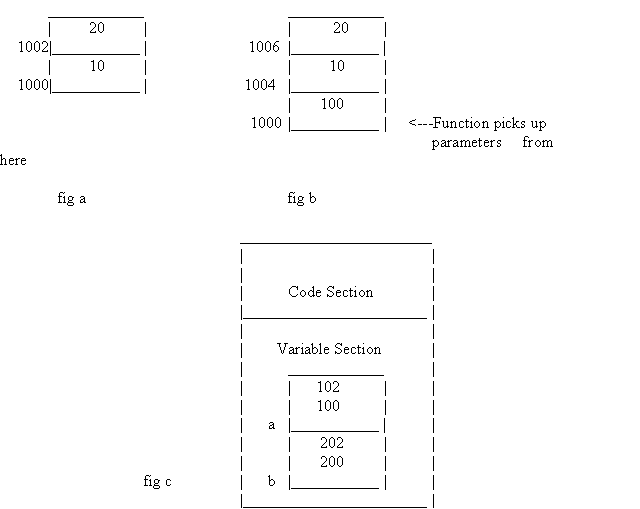
In the function, print(), we have actually displayed the value of this->i and this->j, instead of merely displaying just i and j. We notice that there is absolutely no change in the output, as compared to the previous program. The explanation for this is quite simple. Whenever C++ calls a function, the function gets called with an extra parameter. The extra parameter is called the ' this ' pointer, which points to where the the variables are located in memory. Now, if C++ came across the variable i, standing all alone, it replaced it with the term ' this->i ', internally. Similarly, all other functions in a class also have the same extra parameter called the ' this ' pointer. In fact, when a function in C++ is called with, for example, two parameters, we assume that just these two parameters go on the stack, as shown in fig a.
In reality, an additional parameter also goes onto the stack. This additional parameter contains the address, where the object is located in memory. This is why the function, print, when called by the object 'a', will display only those values of the variables, initialized from that object only. In the figure, we have assumed that the object 'a' is at memory location 100, while
'b' is at 200. We also assumed that our stack is at 1000, in memory. We can observe that the contents of memory location 1000, are pointing to the location of the object 'a' in memory. This is also the point where variables i and j are stored.
It's time to look back at what we have learnt about constructors and inheritance. Here, we have a very simple program with two classes. We have named the constructors according to the name of their class as well as their parameters. For example, the constructors of class zzz have been called 'zzz void', 'zzz one', ' zzz two'... depending on whether they have they have no parameters, one parameter, two parameters, and so on. The second class, yyy, contains only a single constructor.
ci1.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
i=0; j=0;
printf("In zzz void\n");
}
zzz(int x)
{
i=x; j=0;
printf("In zzz one\n");
}
zzz(int x, int y)
{
i=x; j=y;
printf("In zzz two\n");
}
print()
{
printf("From print i=%d...j=%d\n",i,j);
}
};
class yyy
{
public:
yyy()
{
printf("In yyy void\n");
}
};
main()
{
zzz a;
a.print();
zzz b(1);
b.print();
zzz c(2,3);
c.print();
yyy d;
}
The output of this simple program is as follows:
In zzz void From print i=0...j=0 In zzz one From print i=1...j=0 In zzz two From print i=2...j=3 In yyy void
The constructors are called in the expected sequence. At this point in time, we cannot make use of statements like 'yyy e(4);' or 'd.print();' , as the matching constructors or functions do not exist. We now make a minor change to our program, in the sense that we have now replaced 'class yyy' by' class yyy: public zzz', at the beginning of the second class. This seemingly minor change will, however, result in pretty major changes in the working of the entire program. It's not merely the fact that the object 'd' may now make use of all variables and functions present in class zzz. It is much more than that. Because, the statement 'yyy d;' does not result in the creation of just one object of class yyy, as in the earlier program. What this statement results in, is the creation of two objects. Proving this statement, is precisely what we shall be doing, in the next program.
ci2.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
i=0; j=0;
printf("In zzz void\n");
}
print()
{
printf("From print i=%d...j=%d\n",i,j);
}
};
class yyy:public zzz
{
public:
yyy()
{
printf("In yyy void\n");
}
};
main()
{
yyy d;
d.print();
}
OUTPUT:
In zzz void In yyy void From print i=0...j=0
As we may observe, the output of this program shows that two void constructors have been called. We also observe that, in sequence, the base void constructor has been called before the void constructor of the derived class. Of course, only when an object of a class is created, can the constructor be called. Which only goes to prove that, when we execute the above program, two objects are created. Now, we shall try to obtain similar results using constructors with one parameter. In both classes, only the constructors with one parameter are retained, with everything else being deleted.
ci3.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x)
{
i=x; j=0;
printf("In zzz one\n");
}
print()
{
printf("From print i=%d...j=%d\n",i,j);
}
};
class yyy:public zzz
{
public:
yyy(int p)
{
printf("In yyy one\n");
}
};
main()
{
yyy d(5);
d.print();
}
Unfortunately, we now get an error saying that C++ cannot find the default constructor to initialize base class zzz. In other words, while the correct constructor with a single parameter of class yyy has been called, the constructor with one parameter in class zzz hasn't been called. So, why did this happen ? Is it because some other constructor is the default constructor, which has to be called from the base class ? The only way to find out, is to experiment. Let us place three constructors in class zzz.
ci4.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
i=0; j=0;
printf("In zzz void\n");
}
zzz(int x)
{
i=x; j=0;
printf("In zzz one\n");
}
zzz(int x, int y)
{
i=x; j=y;
printf("In zzz two\n");
}
print()
{
printf("From print i=%d...j=%d\n",i,j);
}
};
class yyy:public zzz
{
public:
yyy(int p)
{
printf("In yyy one\n");
}
};
main()
{
yyy d(5);
d.print();
}
OUTPUT:
In zzz void In yyy one From print i=0...j=0
Before we can jump to conclusions, let us take one more example. Here, we have only the constructor with two parameters in class yyy.
ci5.cpp
#include<stdio.h>
class zzz
{
public:
int i, j;
zzz()
{
i=0; j=0;
printf("In zzz void\n");
}
zzz(int x)
{
i=x; j=0;
printf("In zzz one\n");
}
zzz(int x, int y)
{
i=x; j=y;
printf("In zzz two\n");
}
print()
{
printf("From print i=%d...j=%d\n",i,j);
}
};
class yyy:public zzz
{
public:
yyy(int p, int q)
{
i = p; j = q;
printf("In yyy two\n");
}
};
main()
{
yyy d(6,7);
d.print();
}
OUTPUT:
In zzz void In yyy two From print i=6...j=7
Once again, the first constructor to get called, is the zzz void constructor.Now, we can safely conclude that the default constructor, called from the base class, is always the constructor with no parameters. As you may have noticed, we have made an additional change, wherein we assigned the parameters of the 'yyy two' constructor to i and j, resulting in their values now being displayed as 6 and 7, respectively.
It's now time to look for answers as to why only the void constructor is called from the base class, and not the other constructors. When we derive class yyy from class zzz, at each and every constructor of yyy, C++ places information as to where to jump next. Consider the program that we just did. Class yyy actually appears, to C++, as shown below.
class yyy:public zzz
{
public:
yyy(int p, int q) : zzz()
{
i = p; j = q;
printf("In yyy two\n");
}
};
When C++ first creates an object of class yyy, it jumps to the appropriate constructor of class yyy, first. It also knows that since class yyy is derived from zzz, it has to jump to a constructor of class zzz, as well. In our previous programs, however, it finds no information at the constructor of yyy, as to where it should be going next. So, after the name of this constructor, it automatically goes and inserts a ' : ' followed by the name of the default constructor in the base class, zzz( ). This is the location, where C++ has to jump, next. When it reaches zzz( ), the statements within this constructor are executed. After this, C++ jumps back to the original constructor within the derived class, that is yyy(int p, int q), which is now executed. Therefore, in the output, we see that the void constructor of the base class is called before the constructor of the derived class. After all that jumping around, your head might be spinning around. In that case, take a break, because, when we come back, we've got even more jumping to do.
If C++ could tell the constructor of the derived class where to go, there's nothing that prevents us from doing the same. All we have to do is place the name of the desired constructor of the base class preceeded by a ' : ' , after the name of the constructor in the derived class. For example, if we now wish to go to the constructor with one parameter of the base class, from yyy(int p, int q), we merely replace
yyy(int p, int q) by yyy(int p, int q) : zzz( p).
ci6.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
i=0; j=0;
printf("In zzz void\n");
}
zzz(int x)
{
i=x; j=0;
printf("In zzz one\n");
}
zzz(int x, int y)
{
i=x; j=y;
printf("In zzz two\n");
}
print()
{
printf("From print i=%d...j=%d\n",i,j);
}
};
class yyy : public zzz
{
public:
yyy(int p, int q) : zzz(p)
{ i=p; j=q;
printf("In yyy two\n");
}
};
main()
{
yyy d(8,9);
d.print();
}
OUTPUT:
In zzz one In yyy two From print i=8...j=9
In this program, we have managed to avoid calling the default constructor of the base class. Instead, the constructor of class zzz that we specified, has been called. After the name of the constructor of yyy, if we had, instead placed ' : zzz(2,3) ', obviously, the constructor of zzz that will be called, is the one with two parameters, zzz(int i, int j).
In case we get tired of working with only the yyy constructor having two parameters, we could shift to doing something similar with all the yyy constructors.
ci7.cpp
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz()
{
i=0; j=0;
printf("In zzz void\n");
}
zzz(int x)
{
i=x; j=0;
printf("In zzz one\n");
}
zzz(int x, int y)
{
i=x; j=y;
printf("In zzz two\n");
}
print()
{
printf("From print i=%d...j=%d\n",i,j);
}
};
class yyy:public zzz
{
public:
yyy(): zzz(7)
{
printf("In yyy void\n");
}
yyy(int p):zzz(2,3)
{
i=p;
printf("In yyy one\n");
}
yyy(int p,int q)
{
i=p; j=q;
printf("In yyy two\n");
}
};
main()
{
yyy d;
d.print();
yyy e(8);
e.print();
yyy f(4,5);
f.print();
}
OUTPUT:
In zzz one In yyy void From print i=7...j=0 In zzz two In yyy one From print i=8...j=3 In zzz void In yyy two From print i=4...j=5
The output only confirms what we have being saying. As you may observe, everytime we try to create an object of a derived class, the constructor of the base class that we specified executes, first. Following this, C++ executes the constructor of the derived class. In case we hadn't specified the name of the constructor of the base class that has to be called, C++ will automatically call the default constructor, which is the void constructor, zzz().
A minor deviation from our current topic is now called for. We have a C program with a pointer to an int and a pointer to a char. Are we able to equate them to each other ?
ci8.c : ci8.cpp:
main() main()
{ {
int *i; int *i;
char *j; char *j;
i=j; i=j;
} }
When the C program compiles, it does not give us any errors. In other words, C allows us to equate pointers to two different datatypes. We do not, however, have the same kind of luck with C++. C++ will just stop compiling, and tell us that we cannot convert char* to int*. Makes sense to us, at least. After all, can we convert apples to oranges ? Even if the answer to that question is no, it would not be for lack of trying, on our part.
In the program that follows, we have two classes. We have merely created pointers to these two classes. We now want to know whether C++ allows us to equate the two pointers.
ci9.cpp
class zzz
{
public:
int i,j;
};
class yyy
{
public:
int k;
};
main()
{
zzz *a;
yyy *b;
a=b;
}
Error ! Error! C++ is quite clear about one thing. Here, ' a ' is a pointer to one class, while ' b ' is a pointer to a totally different class. We just cannot equate them. We therefore get an error as follows : Cannot convert yyy* to zzz* . If we have the line ' b = a; ' instead of ' a = b; ' , the error would be ' Cannot convert zzz* to yyy* '. This is not too different from trying to equate a pointer to an int with a pointer to a char. After all, even 'int' and 'char' are classes in C++. But what happens if we derive class yyy from class zzz ?
ci10.cpp
class zzz
{
public:
int i,j;
};
class yyy : public zzz
{
public:
int k;
};
main()
{
zzz *a;
yyy *b;
a=b;
}
Yeah ! The error has totally vanished. So we can, after all, equate pointers to different classes, if one class is derived from the other. If we could say ' a = b; ', we could also have ' b = a; ', which is what we shall try in the next program.
ci11.cpp
class zzz
{
public:
int i,j;
};
class yyy : public zzz
{
public:
int k;
};
main()
{
zzz *a;
yyy *b;
b=a;
}
To our utter surprise, we still get the error, ' Cannot convert zzz* to yyy* '. We now have to analyse exactly what went wrong with this program. When we have the line ' a = b; ', we have to understand that, ' a ' and ' b ' actually represent two classes. Therefore on the right hand side of this statement, we have a class yyy, while the left hand side represents class zzz. Since class yyy is derived from class zzz, ' b ' represents a combination of both class zzz as well as class yyy, while ' a ' represents just class zzz. In other words, ' b ' is the bigger class. This is as shown in the figure.
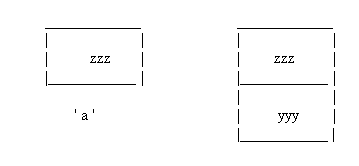
Thus the pointer to the right in the line ' a = b; ', points to a greater content than the pointer to the left of the equal-to sign. The pointer on the left will say that it only needs a ' zzz ' on the right hand side. If you, however, want to give it more than it really needs, it will, quite happily, let you know that it has no problems, what-so-ever. After all, if I expect a salary of only a thousand dollars per month, but you are willing to give me two thousand five hundred, would I be complaining ?
But if I estimated my own worth at two thousand five hundred dollars, and you are offering me a mere thousand, I don't think I would be interested. Similarly, we cannot give ' b ' anything less than what it expects. When we use ' b = a;', ' b ' demands nothing less than the combination of class zzz, as well as class yyy on the right hand side of the equal-to sign. But, in this statement, we are merely giving ' b ', a class zzz. It will definitely come back and say 'ERROR!'. Rules are rules. So, is this the end of the road. No, never. Didn't we mention something earlier about breaking the rules ? Something called casting.
ci12.cpp
class zzz
{
public:
int i,j;
};
class yyy : public zzz
{
public:
int k;
};
main()
{
zzz *a;
yyy *b;
b=(yyy *)a;
}
By casting, all that we have done is inform ' b ' that ' a ' is now of type 'pointer to class yyy'. We are not, however, changing ' a ' in any way. Since ' b ' had been expecting exactly such a thing to be present on the right hand side of the equal-to sign, this program compiles without any problems.
Let's summarise what we have done in the last four programs. A pointer to a derived class can only be on the right of an equal-to sign, while the pointer to the base class can only be on the left. After all, the rules state that a bigger class can be assigned to a smaller class, but a smaller class can't be assigned to a bigger class. The only way to break these rules is by casting.
Memoirs of a Variable
Consider the following C program
st1.c:
main()
{
int i;
for(i=0;i<=10;i++)
abc();
}
abc()
{
int k=5;
k++;
printf("%d\n",k);
}
OUTPUT:
6 6 6 6 6 6 6 6 6 6 6
In this program, when the function abc is called for the first time, in the for loop, k is initialised to 5. As k is incremented by one, the output is 6, for this iteration of the loop. The next time abc is called, k is once again initialised to 5. This results in the program displaying a stream of the number, 6. Such an output may, however, not be the kind of output that we wish to have in certain applications. There might be cases where we want our program to recall the previous value of a particular variable. In such cases, we make use of the keyword 'static'.
st2.c:
main()
{
int i;
for(i=0;i<=10;i++)
abc();
}
abc()
{
static int k=5;
k++;
printf("%d\n",k);
}
OUTPUT:
6 7 8 9 10 11 12 13 14 15 16
The only change in this program is that k has now been declared to be static. The first time function abc is called, k, as usual is initialised to 5. The value of k now becomes 6 when we say k++. This is the output, the first time function abc is called. However, now that the variable k has been declared to be static, the next time function abc is called, C does not look at the line ' k=5; ' at all. Instead, the last value of the variable, which is 6, is remembered. This value is now assigned to k. This value is incremented, and displayed as 7. Thus, when the entire program executes, we see the value of k increasing, each time it is displayed. Placing the term 'static' before a variable, ensures that the variable recollects the value it held, the last time it was accessed.
A static variable behaves like a global variable, with a minor difference. It doesn't have the visibility of a global variable. Had k been a global variable, it would have been visible within main() as well as with the function abc. However, a static variable is visible only within the function in which it has been declared.
It's probably time we got back to C++ programming. The program that follows, is similar to examples that we have done before.
st3.cpp:
#include<stdio.h>
class zzz
{
public:
int i;
zzz()
{
i=6;
printf("Addr of i in constr: %p..\n",&i);
}
void print()
{
printf("In print: %d....%p\n",i,&i);
}
};
main()
{
zzz a;
a.print();
zzz b;
b.print();
zzz c;
c.print();
}
OUTPUT:
Addr of i in constr: 0A02:0FFE.. In print: 6....0A02:0FFE Addr of i in constr: 0A02:0FFC.. In print: 6....0A02:0FFC Addr of i in constr: 0A02:0FFA.. In print: 6....0A02:0FFA
We have a class zzz, with a variable i, a single constructor, and a function, print(). The variable i has been initialised to 6 in the constructor of this class. When we create an object 'a' of this class, C++ will allocate some memory for this object, and also call the constructor. Within the constructor, we have printed the address of the variable i.
When we use terms such as a.print() or a.i, what we mean is that the variable i, or the function print(), belong solely to the object a. The line 'a.print();' in our program, displays the value as well as the address of the variable 'i'. Since it is the object 'a' that is calling print(), effectively, what is being displayed, is 'a.i', that is, the variable i, whose owner is the object 'a'.
In this program, we have created two additional objects of the class zzz. These are 'b' and 'c'. We notice that each time the constructor is called, a different address will be displayed for i. Furthermore, the address in the constructor will match the address that is displayed every time the function print() is called by the object. Thus, we may safely state that the variable i belongs to the object that is calling it. Although this variable has been declared as well as initialized within class zzz, it does not belong to the class. In order to further prove this point, we introduce a minor variation in our previous program.
st4.cpp:
#include<stdio.h>
class zzz
{
public:
int i;
zzz()
{
i=6;
printf("Addr of i in constr: %p..\n",&i);
}
void print()
{
printf("In print: %d....%p\n",i,&i);
}
};
main()
{
zzz a;
a.i++;
a.print();
zzz b;
b.print();
zzz c;
c.print();
}
OUTPUT:
Addr of i in constr: 111C:0FFE.. In print: 7....111C:0FFE Addr of i in constr: 111C:0FFC.. In print: 6....111C:0FFC Addr of i in constr: 111C:0FFA.. In print: 6....111C:0FFA
In the above program, we have added the line ' a.i++; '. Due to this, the value of i displayed is now 7, when ' a.print(); ' is executed. In the program, the function print is also called, by both, the object 'b', as well as the object 'c'. This function will display the same variable i, that has been declared within the class. However, as we stated before, even though i is present in the class zzz, it belongs exclusively to the object that is accessing it. The i of one object, has nothing to do with the i of another object, even though both objects may be of the same class. This is why, when print is called by 'b' and 'c', the output is 6, the same as in the previous program.
The whole thing reminds me of the tube of toothpaste, at home. Although within an apartment, it doesn't belong to the apartment, itself. It belongs to, and is used by people, who are members of the family that reside in the apartment.
Is it possible for a variable present within a class to actually belong to a class? If such a thing were to happen, the address of the variable would not change everytime an object to the class was created.
st5.cpp:
#include<stdio.h>
class zzz
{
public:
static int i;
zzz()
{
printf(" In constr i=%d",i);
}
};
main()
{
zzz a;
printf("%d\n",a.i);
}
The variable in the above program has been declared to be static. We have created an object of the class zzz called 'a', as we normally do. Within main(), we do not try to print i, standing all alone. Since 'i' is associated with the object of the class, we normally print 'a.i'.
When we try to run this program, we get a linker error saying 'Undefined symbol zzz::i ....'.
The problem with making a variable static, is that we have to initialize the variable outside the class. To denote that we are initializing the variable i, that only belongs to class zzz, we make use of the '::' operator. At the end of the class zzz in our program, we include the line ' int zzz::i= 10; '. We cannot just say ' zzz::i=10; ', even though we have already stated that i is an 'int' within class zzz. Doing so, would give us an error saying 'type name expected'.
st6.cpp:
#include<stdio.h>
class zzz
{
public:
static int i;
zzz()
{
i++;
printf(" In constr i=%d",i);
}
};
int zzz::i=10;
main()
{
zzz a;
printf("In main i=%d\n",a.i);
}
OUTPUT:
In constr i=11 In main i=11
The program now executes, without any problems. At this point, however, some doubts rake through our mind. We have initialized the variable from outside the class, but to do so, we didn't make use of the object of the class. In other words, we did not say 'a.i=10;'. In that case, within main(), do we need to create an object at all, to access the variable i ?
st7.cpp:
#include<stdio.h>
class zzz
{
public:
static int i;
};
int zzz::i=10;
main()
{
printf("In main i=%d\n",zzz::i);
}
OUTPUT:
In main i=10
We have not created an object at all, in this program. A constructor will, therefore, never be called. But we have still managed to access a variable within a class, once again, by saying zzz::i
We shall now create three objects of the class zzz, and everytime the constructor is called, we shall display the value as well as the address of the variable i. Also, within the constructor, we have incremented the value of i.
st8.cpp:
#include<stdio.h>
class zzz
{
public:
static int i;
zzz()
{
i++;
printf("In constr i= %d...Addr=%p\n",i,&i);
}
};
int zzz::i=10;
main()
{
zzz a;
printf("a.i=%d\n",a.i);
zzz b;
printf("b.i=%d\n",b.i);
zzz c;
printf("c.i=%d\n",c.i);
}
OUTPUT:
In constr i=11..Addr=10D7:0094 a.i=11 In constr i=12..Addr=10D7:0094 b.i=12 In constr i=13..Addr=10D7:0094 c.i=13
We are definitely in for a surprise. In fact, the output is something we totally did not expect. Everytime we create an object and thereby call the constructor, the value of i is not reinitialized to 10. Instead, i retains the value it last held. Since we are incrementing i everytime the constuctor is called, we see an ever increasing value of i displayed. An even greater surprise is that, the address of i displayed, each time, is always the same. We therefore conclude that, by declaring i to be a static variable, i no longer belongs to the object of the class, but to the class, itself. This variable now remembers the value it held when it was last accessed.
st9.cpp:
#include<stdio.h>
class zzz
{
public:
static int i;
zzz()
{
i++;
printf("In constr i= %d..%p\n",i,&i);
}
void print()
{
printf("In print i= %d..%p\n",i,&i);
}
};
int zzz::i=10;
main()
{
printf("zzz::i= %d\n",zzz::i);
zzz a;
a.print();
zzz b;
b.print();
zzz c;
c.print();
}
OUTPUT:
zzz::i= 10 In constr i= 11..10D9:0094 In print i= 11..10D9:0094 In constr i= 12..10D9:0094 In print i= 12..10D9:0094 In constr i= 13..10D9:0094 In print i= 13..10D9:0094
In this program, we have only confirmed what we have been saying about static variables. We observe that, once again, the address displayed is always the same.
Time to recap what we have learnt about static variables, so far. To access a static variable, we do not need to create an object. This is why, to access i from class zzz, we may simply make use of ' zzz::i '. In other words, we can get such a variable absolutely free from a class, without taking all the trouble to create an object of the class. In fact, instead of calling such variables static, we should be calling them free. A static variable will always be owned by a class, and not by the objects of the class.
We may have an application which needs to know what the value of a variable in a class was, when it was last accessed. Based on this value, various options to proceed ahead, may be chosen. This variable may now have a new value assigned to it. The next time we access this variable, we may do so from a different object, but we still need to know what the variable's last value was. To do so, we make the variable 'static'.
It's not only variables that can be defined to be static. We may also have functions that are declared to be static. The rules remain the same. We don't have to create objects to access these functions. In fact, whole classes may be declared static. The whole idea is that, whatever is declared to be static, can be access absolutely free.
Extern ? Not Defined Here.
Time and time again, we fall back to revise our basics of the C programming language. It's only when these are strong, can we actually learn C++. Consider the following C program.
e1.c:
main()
{
printf("%p\n",&i);
abc();
}
Obviously, when we compile the above program, we shall get a compiler error saying 'undefined external symbol i...'. We shall now include the line 'extern int i;' at the start of the program, before main(). In other words, globally.
e2.c:
extern int i;
main()
{
printf("main..%p\n",&i);
abc();
}
We now merely compile this program, but do not link it. The compiler will not give us any errors. We cannot possibly link it because the function abc is not present within the progam. When we write the word 'extern' before a variable, we are saying that this variable has not been ceated here. Instead, it has been created somewhere else. So, somewhere else, is where we should be going.
e3.c:
int i;
abc()
{
printf("abc %p",&i);
}
This program contains the function abc and a variable i, but no main().Once again, we only compile the program, but do not build it. We get no errors. We now click on the word 'Project' in the toolbar at the top of our screen. We then select 'Open Project', and write the name of the project we wish to open. In this case, we have chosen 'e.prj'. At the bottom of our screen, a small window opens up, giving us the names of the files present in the project. Right now, there are none. So, we once again, click on Project. We now select 'AddItem' from the options. Here, we first write e2.c and click on 'add' , after which we write e3.c in the textbox, and once again click on 'add'. We now click on 'done' to indicate that our project is complete. When we now select Compile in the toolbar and then build, we get a file called e.exe. When we execute this function, the output is as follows.
main 10CA:0380 abc 10CA:0380..
As we can see, the addresses displayed by the two programs are exactly the same. This confirms that i had been defined in e3.c, and the same variable is also being used by e2.c because we had declared it to be 'extern'.
Virtually, All Your's
Throughout the ages, philosophers and great thinkers have always had one bad habit. They said things that no one understood. Many of them suggested that we are living in a virtual world, a world built around our own illusions. We never really understood exactly what they meant by this, but C++ has taken us right up to the edge of reality, using virtual functions.
Whenever we start a new topic, we always begin with a very simple program, often similar to one we had done earlier. We waste absolutely no time, and immediately get on to the first program in this topic.
vr1.cpp:
#include<stdio.h>
class zzz
{
public:
void abc(){printf("zzz abc\n");}
void pqr(){printf("zzz pqr\n");}
void xyz(){printf("zzz xyz\n");}
} ;
class yyy
{
public:
void abc(){printf("yyy abc\n");}
void pqr(){printf("yyy pqr\n");}
void aaa(){printf("yyy aaa\n");}
};
main()
{
zzz *a;
a=new zzz;
a->abc(); a->pqr(); a->xyz();
yyy *b;
b=new yyy;
b->abc(); b->pqr(); b->aaa();
}
OUTPUT:
zzz abc zzz pqr zzz xyz yyy abc yyy pqr yyy aaa
The explanation of this program is simple enough. We have two classes, each containing three functions. The function, xyz, is present only in class zzz, while the function, aaa, is present only in class yyy. The other two functions, abc and pqr, are present in both classes. Here, 'a' has been declared to be a pointer to class zzz, and 'b' is a pointer to class yyy. By saying ' a=new zzz;' and ' b=new yyy; ', we have created objects 'a' and 'b' of classes zzz and yyy, respectively. The sequence in which the functions are called in this program, is as shown in the output. We cannot say b->xyz(), or a->aaa(), because 'a' can only access those functions that are present in class zzz, while 'b' can only access those functions present in class yyy. Both 'a' and 'b' are two distinct objects. If we now derive class yyy from class zzz, we may use 'b' to access any function within zzz.
We now consider a case when we declare d to be a pointer to class zzz. Now, after deriving class yyy from class zzz, we say ' d = new yyy ', as opposed to saying ' d = new zzz '. It's time to investigate how this affects our program.
vr2.cpp:
#include<stdio.h>
class zzz
{
public:
void abc(){printf("zzz abc\n");}
void pqr(){printf("zzz pqr\n");}
void xyz(){printf("zzz xyz\n");}
} ;
class yyy : public zzz
{
public:
void abc(){printf("yyy abc\n");}
void pqr(){printf("yyy pqr\n");}
void aaa(){printf("yyy aaa\n");}
};
main()
{
zzz *d;
d=new yyy;
d->abc();
d->pqr();
d->xyz();
}
OUTPUT:
zzz abc zzz pqr zzz xyz
Class yyy is derived from class zzz. Therefore, the statement ' d = new yyy; ' is valid, in spite of the fact that 'd' is a pointer to class zzz. From the output, we find that abc and pqr are called from class zzz, and not from class yyy. In fact, all the functions that we have tried to call so far, belong to class zzz. What happens when we try to call a function that is present only in class yyy ?
vr3.cpp:
#include<stdio.h>
class zzz
{
public:
void abc(){printf("zzz abc\n");}
void pqr(){printf("zzz pqr\n");}
void xyz(){printf("zzz xyz\n");}
} ;
class yyy : public zzz
{
public:
void abc(){printf("yyy abc\n");}
void pqr(){printf("yyy pqr\n");}
void aaa(){printf("yyy aaa\n");}
};
main()
{
zzz *d;
d=new yyy;
d->abc();
d->pqr();
d->xyz();
d->aaa();
}
Error! Function aaa is not a member of class zzz. The same philosophers that caused us so many problems before, now come to our rescue. They always said that man should learn from his mistakes. Which is why we are not too disappointed with such a small error. We realise that with 'd', we are only able to access the functions that are present in class zzz. The right hand side of the statement ' d = new yyy; '
will return a pointer to both, class zzz as well as class yyy, as yyy is derived from zzz.
However, 'd' has been defined to be a pointer to class zzz only. So, despite the fact that the functions of both zzz as well as yyy are present in memory location which 'd' points to, the compiler will not allow 'd' to access any function that is in class yyy. Whenever we try to call a function using 'd', 'd' will immediately check what 'd' points to. Since it points to class zzz, only those functions in zzz can be called.
We would not have had any of these problems, had 'd' just been declared a pointer to class yyy. It would have then been able to access the functions of both yyy as well as zzz. But in our program, this is not the case.
In the next program, we have made only a single change, from vr2.cpp, in the sense that we have added the word 'virtual' in front of the function abc(), in class zzz. As soon as we write this word, it's colour changes on the screen, indicating that it is a reserved word, one that C++ recognises. The effect of this one word can be witnessed in the next program.
vr4.cpp:
#include<stdio.h>
class zzz
{
public:
virtual void abc(){printf("zzz abc\n");}
void pqr(){printf("zzz pqr\n");}
void xyz(){printf("zzz xyz\n");}
} ;
class yyy : public zzz
{
public:
void abc(){printf("yyy abc\n");}
void pqr(){printf("yyy pqr\n");}
void aaa(){printf("yyy aaa\n");}
};
main()
{
zzz *d;
d=new yyy;
d->abc();
d->pqr();
d->xyz();
}
OUTPUT:
yyy abc zzz pqr zzz xyz
Is it time to junk all that we said about C++ not allowing 'd' to call any function that is not present in the class, it has been defined to point to? Because, in our output, we see that abc has now been called from class yyy, the derived class.
Here, 'd' is a pointer to class zzz. That is why, when we say 'd->abc();' , 'd' will first go to the function abc() in class zzz. If abc() in class zzz is not virtual, as in vr2.cpp, this is the function that is called. But if it is virtual, 'd' will look at what it was initialised to. In our program, by the statement
' d = new yyy; ' , we have initialised 'd' to be an object of class yyy. Because it was initialised to yyy,
'd' will call function abc() that is in class yyy. Putting the term virtual in front of abc in class yyy will not make any change in the resulting output of this program. As long as abc in the base class is virtual, abc will still be called from class yyy. But what happens if abc is virtual only in yyy, and not in zzz ?
vr5.cpp:
#include<stdio.h>
class zzz
{
public:
void abc(){printf("zzz abc\n");}
virtual void pqr(){printf("zzz pqr\n");}
virtual void xyz(){printf("zzz xyz\n");}
} ;
class yyy : public zzz
{
public:
virtual void abc(){printf("yyy abc\n");}
void pqr(){printf("yyy pqr\n");}
void aaa(){printf("yyy aaa\n");}
};
main()
{
zzz *d;
d=new yyy;
d->abc();
d->pqr();
d->xyz();
}
OUTPUT:
zzz abc yyy pqr zzz xyz
As we mentioned earlier, 'd' first looks at what it has been defined as. Since 'd' has been defined as a pointer to class zzz, it will first go there to look for function abc(). Since the term is not present in front of abc, the function is called from here itself. Putting 'virtual' in front of abc in class yyy has absolutely no effect.
We have also made functions pqr and xyz virtual in class zzz. In the case of pqr, as in program vr4.cpp, it is called from class yyy. However, the function xyz is not present in class yyy. So even if it wanted to, C++ cannot call function xyz from class yyy. It simply moves on to the next best alternative and calls xyz from class zzz.
We have to realise that we cannot have statements like
yyy *e; e = new zzz;
We have to remember our earlier theory of smaller and bigger classes. Since the derived class contains all it's own functions, as well as the functions present in the base class, the derived class has to be larger. As we have defined 'e' to be a pointer to class yyy, if 'e' has to be equated to something present on the right of an equal-to sign, it demands a yyy, or something derived from yyy. As we are merely giving 'e', a zzz on the right hand side of the equal-to sign, in the second statement, it will definitely give us an error
In our next program, we define 'p' to be pointer to class zzz, as we have done in the previous examples. We, however, now define an additional class, xxx, that is derived from class yyy, and initialise 'p' to be an object of class xxx.
vr6.cpp:
#include<stdio.h>
class zzz
{
public:
void abc(){printf("zzz abc\n");}
void pqr(){printf("zzz pqr\n");}
void xyz(){printf("zzz xyz\n");}
} ;
class yyy : public zzz
{
public:
void abc(){printf("yyy abc\n");}
void pqr(){printf("yyy pqr\n");}
void aaa(){printf("yyy aaa\n");}
};
class xxx:public yyy
{
public:
void abc(){printf("xxx abc\n");}
void bbb(){printf("xxx xxx aaa\n");}
};bbb\n");}
void aaa(){printf("
main()
{
zzz *f;
f=new xxx;
f->abc();
f->pqr();
f->xyz();
}
OUTPUT:
zzz abc zzz pqr zzz xyz
In this program, 'p' has been initialised to be an object of class xxx. Therefore, in memory,
'p' points to class xxx, class yyy as well as class zzz.

But, since 'p' has been defined as a pointer to class zzz, it does not look beyond zzz. In fact, it cannot access any function from either class xxx or yyy. It can access only those functions that are in class zzz. These rules have already been discussed earlier. If we want 'p' to access any function present in either class xxx or class yyy, we have to make that function virtual in class zzz.
vr7.cpp:
#include<stdio.h>
class zzz
{
public:
virtual void abc(){printf("zzz abc\n");}
virtual void pqr(){printf("zzz pqr\n");}
virtual void xyz(){printf("zzz xyz\n");}
} ;
class yyy : public zzz
{
public:
void abc(){printf("yyy abc\n");}
void pqr(){printf("yyy pqr\n");}
void aaa(){printf("yyy aaa\n");}
};
class xxx:public yyy
{
public:
void abc(){printf("xxx abc\n");}
void bbb(){printf("xxx bbb\n");}
void aaa(){printf("xxx aaa\n");}
};
main()
{
zzz *f;
f=new xxx;
f->abc();
f->pqr();
f->xyz();
}
OUTPUT:
xxx abc yyy pqr zzz xyz
Here, functions abc, pqr, and xyz are all called from different classes. This, in no way, means that there has been any change in the rules that govern the calling of functions.
Function abc is present in all three classes. As 'p' is a pointer to class zzz, it will first look at class zzz. Since class abc is virtual, 'p' then looks at what it has been initialised to, that is, class xxx. This is where function abc will be called from. In the case of function pqr, when 'p' finds that it is virtual in class zzz, it then looks at class xxx. But this function is not present in class xxx. C++ then settles for the function, in the class yyy, that is, the class from which xxx is derived. In the case of function xyz, it is not present anywhere, except in class zzz. So this is the only place where it can be called from.
We thus notice that, if a function is virtual in the base class, in all the derived classes, it automatically becomes virtual. Also, the last occurance of the virtual function is being called, when we go from the base class, downwards. If we make all the functions in class yyy, virtual, there is absolutely no change in the output of the above program.
The complexities in all the above programs arise, because we defined a pointer to a smaller class, but created an object to a larger class.
In subsequent programs, we no longer define a pointer to class zzz, but instead, define a pointer to class yyy. As in the last program, we then initialise it to be an object of class xxx.
vr8.cpp:
#include<stdio.h>
class zzz
{
public:
void abc(){printf("zzz abc\n");}
void pqr(){printf("zzz pqr\n");}
void xyz(){printf("zzz xyz\n");}
} ;
class yyy : public zzz
{
public:
void abc(){printf("yyy abc\n");}
void pqr(){printf("yyy pqr\n");}
void aaa(){printf("yyy aaa\n");}
};
class xxx:public yyy
{
public:
void abc(){printf("xxx abc\n");}
void bbb(){printf("xxx bbb\n");}
void aaa(){printf("xxx aaa\n");}
};
main()
{
yyy *f;
f=new xxx;
f->abc();
f->pqr();
f->xyz();
f->aaa();
}
OUTPUT:
yyy abc yyy pqr zzz xyz yyy aaa
We are now able to call all the functions that are present in class yyy, as well as in class zzz. This is because class yyy is derived from class zzz, and we can call an additional function, xyz. As usual, these are all called from the class that 'f' is defined to point to, that is, class yyy. This is not the case for the function xyz. This function, being present in class zzz, is called from there.
We shall now make all the functions in class zzz 'virtual'.
vr9.cpp:
#include<stdio.h>
class zzz
{
public:
virtual void abc(){printf("zzz abc\n");}
virtual void pqr(){printf("zzz pqr\n");}
virtual void xyz(){printf("zzz xyz\n");}
} ;
class yyy : public zzz
{
public:
void abc(){printf("yyy abc\n");}
void pqr(){printf("yyy pqr\n");}
void aaa(){printf("yyy aaa\n");}
};
class xxx:public yyy
{
public:
void abc(){printf("xxx abc\n");}
void bbb(){printf("xxx bbb\n");}
void aaa(){printf("xxx aaa\n");}
};
main()
{
yyy *f;
f=new xxx;
f->abc();
f->pqr();
f->xyz();
f->aaa();
}
OUTPUT:
xxx abc yyy pqr zzz xyz yyy aaa
If we make a function virtual in the base class, it automatically becomes virtual in the derived class. Which is why function abc will be called from xxx. Also, only the last occurance of the function is called, when we go down, starting from the base class. This is why pqr gets called from class yyy. As xyz is present only in class zzz, this is where it is called from. We haven't, however, made function aaa, virtual. Therefore, 'f' will just look at what it has been initialised to, and pick up function aaa from class yyy. In the case of xyz, there is no other alternative, other than calling it from class zzz.
vr10.cpp:
#include<stdio.h>
class zzz
{
public:
void abc(){printf("zzz abc\n");}
void pqr(){printf("zzz pqr\n");}
void xyz(){printf("zzz xyz\n");}
} ;
class yyy : public zzz
{
public:
void abc(){printf("yyy abc\n");}
void pqr(){printf("yyy pqr\n");}
virtual void aaa(){printf("yyy aaa\n");}
};
class xxx:public yyy
{
public:
virtual void abc(){printf("xxx abc\n");}
void bbb(){printf("xxx bbb\n");}
void aaa(){printf("xxx aaa\n");}
};
main()
{
yyy *f;
f=new xxx;
f->abc();
f->pqr();
f->xyz();
f->aaa();
}
OUTPUT:
yyy abc yyy pqr zzz xyz xxx aaa
Once again, 'f' will first look at what it has been defined to point to. Since it points to class yyy, it calls function abc() from there. The fact that abc is virtual in class xxx, or that 'f' is actually an object of the class xxx, makes no difference. However, since aaa() is virtual in class yyy, 'f' looks at what class it has been initialised to. Since 'f' has been initialised to be an object of class xxx, function aaa is called from this class.
Virtual functions thus apply only when we have a pointer to a smaller class, but have initialised it to be an object of a larger class. Only the functions that are present in the class to which, the pointer has been defined to point to, can be called. However if the pointer sees the term 'virtual' in front of the function, it looks at the class, to which it has been initialised. In other words, it looks at which class, it is an object of. It will then call the function from this class. If this function is not present in the class to which it has to be initilised to, it call the function from the class it has been derived from.
When programmers speak, they often make use of terms that hardly make sense to us. They often stress the need to introduce modularity in the code we write. What this means, in simple language, is that they want us to break up the applications we write, into a number of programs, so that our final code is easy to debug. Breaking up programs is especially useful when it comes to adding more features in our application. Earlier, we had a simple project in C. We shall now do something similar in C++. C++ needs the prototype of every function that we call. For the sake of convenience, we put all these prototypes into a single file called the header file. In such a header file, we do not put any code. Ideally, even if we add a hundred header files into our project, the size of our project should not change, as they contain absolutely no code.
zzz.h:
#include<stdio.h>
class zzz
{
public:
void abc();
void pqr();
};
class yyy:public zzz
{
public:
void abc();
void pqr();
};
class xxx:public yyy
{
public:
void abc() ;
void pqr();
};
void aaa();
We first create a header file with three class prototypes. As before, we have derived class yyy from class zzz, and class xxx from class yyy. The functions, abc and pqr, are present in each and every class. In addition, we also have the prototype of a function, aaa(), within the header file.
We have given the actual code of these functions, abc and pqr, in a file called zzz.cpp. We, of course, have to distinguish between the function abc that is present in class zzz and the function of the same name present in class yyy or class xxx. If we wish to refer to a function belonging to a class, from outside the class, we use the double colon operator ' :: '. Thus the function, abc(), within class zzz, is referred to as zzz::abc(). By the look of it, the person who wrote C++ was either very fond of colons, or had run out of things to connect a function to it's class. All that we have done, is place a single line of code within each function. This will display which function is being called. At the top of this program, we have included a header file, but we haven't used the angle brackets, '<' and '>', as we usually do. Instead, we have made use of double quotes. By saying #include "zzz.h", we mean that zzz.h is a header file in our current directory.
zzz.cpp:
#include "zzz.h"
void zzz::abc()
{
printf("In zzz abc\n");
}
void zzz::pqr()
{
printf("In zzz pqr\n");
}
void yyy::abc()
{
printf("In yyy abc\n");
}
void yyy::pqr()
{
printf("In yyy pqr\n");
}
void xxx::abc()
{
printf("In xxx abc\n");
}
void xxx::pqr()
{
printf("In xxx pqr\n");
}
In the next file, z1.cpp, we have said that 'a' is a pointer to a class zzz. However, we have defined 'a' to be extern. This means that the actual definition of 'a' has been done in some other file. The file, z1.cpp, is the file that that contains the function, main(). We have initialised a to be an object of class zzz. We have also called a function, aaa(). The code of the function is not present in this file.
z1.cpp:
#include "zzz.h"
extern zzz *a;
main()
{
a= new zzz;
aaa();
}
The last file we have, is called z2.cpp. In this file we have the actual definiition of 'a', as well as the code of the function aaa(). The function aaa() simply contains a call to the function abc() by 'a'.
z2.cpp:
#include "zzz.h"
zzz *a;
void aaa()
{
a->abc();
}
We open a project, and add three files, zzz.cpp, z1.cpp and z2.cpp to our project, z.prj. The detailed explanation on how to go about this process has been explained in a previous example. In short, we click on Project, select OpenProject and give the name of the project. Once again, click on Project, then on AddItem, and give the names of our files, one by one. We finally click on 'Done'. We do not add the header file zzz.h into our project. The compilation and linking of the project will give us no errors.
Before we execute this seemingly complicated project, let us pause a moment to review what we have just written about. In the logical sequence of execution, main() will be called first. Now, main() knows that 'a' is a pointer to a class called zzz. We have now initialised 'a' to be an object of class zzz by saying ' a = new zzz '. We also have a call to a function aaa(). If we look at the code of function aaa(), within z2.cpp, we can see that it contains a call to the function abc(), by 'a'. As 'a' is a pointer to class zzz, function abc will be called from this class. Thus the output of our project will be as shown below.
OUTPUT:
In zzz abc
We now make a minor change to only one of our programs, namely z1.cpp. Here, we initialise 'a' to be an object of class yyy, instead of class zzz. Since class yyy is derived from class zzz, we are allowed to do such a thing.
z1.cpp:
#include "zzz.h"
extern zzz *a;
main()
{
a= new yyy;
aaa();
}
We save this file and recompile our project. We realise that there is absolutely no change in the output of our program. Function abc will still get called from class zzz. Because 'a' is defined as a pointer to class zzz, function abc will be called from this class only. The object 'a' only looks at what it points to. Thus, even if we initialise 'a' to class xxx, when this project executes, function abc is still called from class zzz.
But what if we place the term 'virtual' in front of the prototype of the function abc, in the header file, keeping 'a' initialised to yyy ?
zzz.h:
#include<stdio.h>
class zzz
{
public:
virtual void abc();
void pqr();
};
class yyy:public zzz
{
public:
void abc();
void pqr();
};
class xxx:public yyy
{
public:
void abc() ;
void pqr();
};
void aaa();
OUTPUT:
In yyy abc
When 'a' has to call a function, it first looks at what it has been defined to point to, namely class zzz. It goes out here directly, but finds that function abc is a virtual function. So, 'a' now looks at what it has been initialised to, ie class yyy. This is where it will call function abc from.
Let us modify file z1.cpp again. This time, we initialise 'a' to class xxx. Function abc continues to be virtual in the header file zzz.h.
z1.cpp:
#include "zzz.h"
extern zzz *a;
main()
{
a= new xxx;
aaa();
}
When a function is virtual in class zzz, functions of the same name will be virtual in all classes that are derived from class zzz. Thus, function abc is virtual in classes yyy and xxx, as well. Here 'a' will call abc from the class it has been initialised to. Therefore, when we execute this project, we see that function abc is called from class xxx.
A thought might have crossed our mind. Why haven't we made abc virtual in file zzz.cpp, where the code for the function is placed ? The only way to erase a doubt is to check whether such a thing is possible or not. So, we remove the term 'virtual' in the header file, and place it in front of 'void zzz::abc()' in zzz.cpp.
When we compile our program, we get an error telling us that storage class 'virtual' is not allowed in zzz.cpp. In other words, we have to make abc virtual in the prototype. The function abc cannot be made virtual when the code of the function has been written in a separate file.
Consider the file zzz.cpp. It has absolutely no idea as to what 'a' has been initialised to. Have we said 'a = new zzz' or have we said 'a = new yyy' ? The initialisation has been done in a different C++ file, belonging to the same project. Each C++ file is a separate entity, in itself. One C++ file also has no idea as to what is in another C++ file. In fact, although we can see every instruction, in consequtive statements of a file, the C++ compiler cannot. The C++ compiler doesn't even know what took place in the previous line of a single file. So then, how can we expect it to know what happens in a totally different file. Yet everything works!!! How does this happen ? This will be revealed as we go ahead.
We now go back to our basics. We have a class with three integers and three functions.
th1.cpp:
#include <stdio.h>
class zzz
{
public:
int i,j,k;
void abc()
{
printf("In zzz abc");
}
void pqr()
{
printf("In zzz pqr");
}
void xyz()
{
printf("In zzz xyz");
}
};
main()
{
printf("%d\n", sizeof(zzz));
printf("%p\n",zzz::abc);
printf("%p\n",zzz::pqr);
printf("%p\n",zzz::xyz);
}
OUTPUT:
6 11A7:0069 11A7:007A 11A7:008B
If we look at what the sizeof(zzz) returns, we find that the functions in class zzz haven't been taken into consideration at all.
Sizeof( ) is essentially a function borrowed from C. Suppose there is one integer in a class, the sizeof( ) function will return a value of 2. If we add one more integer in the class, the sizeof() function will tell us that the size of the class is 4. But what if there were no variables in the class ? Wouldn't the sizeof( ) function return 0 ? However , the concept of a class having a size of zero does not exist. This is why the size displayed is 1. Now, if we add a function to class that has two integers, by how much will the value returned by the sizeof( ) function change ? We notice that the addition of a function, or even a hundred functions does not change the value returned by sizeof( ), at all.
Since there are three ints in the class, and each int occupies two memory locations, the size displayed is 6.. The three functions will be stored in separate areas of memory. As before, zzz :: abc refers to the function abc that belongs to the class zzz.
We now create an object 'a' of the class zzz, and display the address at which it starts. We also display the address at which the first variable, i, starts in memory.
th2.cpp:
#include <stdio.h>
class zzz
{
public:
int i,j,k;
void abc()
{ printf("In zzz abc");}
void pqr()
{ printf("In zzz pqr");}
void xyz()
{ printf("In zzz xyz");}
};
main()
{
zzz *a;
a = new zzz;
printf("Size %d\n", sizeof(zzz));
printf("Addr of a %p\n",a);
printf("Addr of a->i %p\n",&a->i);
printf("Addr of abc %p\n",zzz::abc);
printf("Addr of pqr %p\n",zzz::pqr);
printf("Addr of xyz %p\n",zzz::xyz);
}
OUTPUT:
Size 6 Addr of a 11F8:0FFA Addr of a->i 11F8:0FFA Addr of abc 11A7:0092 Addr of pqr 11A7:00A3 Addr of xyz 11A7:00B4
As we can see, the address of where the object starts in memory is the same as address of a->i. The functions will always be stored in a different area of memory. We now make a small change to the above program. In front of the function, abc, in class zzz, we place the term 'virtual'. We do not add any more variables to the class, and within main(), we make absolutely no changes.
th3.cpp:
#include <stdio.h>
class zzz
{
public:
int i,j,k;
virtual void abc()
{ printf("In zzz abc");}
void pqr()
{ printf("In zzz pqr");}
void xyz()
{ printf("In zzz xyz");}
};
main()
{
zzz *a;
a = new zzz;
printf("Size %d\n", sizeof(zzz));
printf("Addr of a %p\n",a);
printf("Addr of a->i %p\n",&a->i);
printf("Addr of abc %p\n",zzz::abc);
printf("Addr of pqr %p\n",zzz::pqr);
printf("Addr of xyz %p\n",zzz::xyz);
}
OUTPUT:
Size 8 Addr of a 11FA:0FF8 Addr of a->i 11FA:0FFA Addr of abc 11A7:00A8 Addr of pqr 11A7:00B3 Addr of xyz 11A7:00C4
When we look at what the sizeof() function returned to us, we notice that the size of class has changed. Have we added any variable in our class ? We definitely haven't. In that case, how has the size of class zzz suddenly become 8. Class zzz clearly takes up two more memory locations.
A look at the next two lines reveal an even bigger surprise. The address of a->i is no longer the same as the address where object 'a' resides in memory. We could try displaying the addresses of a->j and a->k, to see if one of these addresses match the address of 'a'. We shall find that they do not. Doesn't this create a conflict with whatever we have learnt about classes, until now ?
Making a single function virtual caused the increase in size of the class zzz by two. Therefore, making the functions pqr and xyz virtual, as well, should now increase the size of class zzz to occupy an additional 4 bytes of memory, logically speaking. Let us see if this happens, in the next program.
th4.cpp:
#include <stdio.h>
class zzz
{
public:
int i,j,k;
virtual void abc()
{ printf("In zzz abc");}
virtual void pqr()
{ printf("In zzz pqr");}
virtual void xyz()
{ printf("In zzz xyz");}
};
main()
{
zzz *a;
a = new zzz;
printf("Size %d\n", sizeof(zzz));
printf("Addr of a %p\n",a);
printf("Addr of a->i %p\n",&a->i);
printf("Addr of abc %p\n",zzz::abc);
printf("Addr of pqr %p\n",zzz::pqr);
printf("Addr of xyz %p\n",zzz::xyz);
}
OUTPUT:
Size 8 Addr of a 11FF:0FF8 Addr of a->i 11FF:0FFA Addr of abc 11A7:00A8 Addr of pqr 11A7:00C4 Addr of xyz 11A7:00E1
As we can see, only the first time we make a function in class zzz virtual, the size of the class increases by two. Making an additional function of the class virtual, does not further change the size of class zzz.
To explain all the programs we have just done, let's consider the programs where the functions are not virtual. Let's assume that C++ places the variables at a memory location of 500. In other words, the addresses of i, j and k are 500, 502 and 504. The location of i will also be the address of the object 'a' in memory. Let us also assume that the three functions are stored at 600, 620 and 640. This is shown in the figure below.
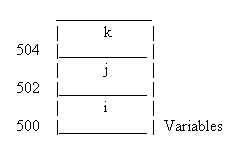
NO FUNCTIONS VIRTUAL IN CLASS
However, if we make one of the functions virtual, the address of the i will no longer start at 500. Instead, the address of i is now 502. In other words, something has been added to our list of variables. If we probe deeper, we shall find that it is some kind of a pointer. The contents of this pointer will be some memory location, in our case, 550 . We now realise that if we look at the contents of this memory location, we find the address of the first function, namely abc.
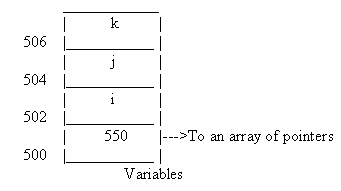
ALL FUNCTIONS VIRTUAL IN CLASS
When even one function in the class is virtual, and we say new, an array of pointers is created somewhere in memory. The first location in the array will contain the starting address of the first virtual function in memory. Only the addresses of the virtual functions are stored in this array. If all three functions in the class are virtual, this array will contain the address 600, 620 and 640 at locations 550, 554 and 558. But if only functions pqr and xyz are virtual, then the array will contain 620 and 640 at memory locations 550 and 554, respectively.
At the end of the class, all the functions are placed at some position in memory. Who is responsible for creating this array of pointers to the functions ? It is definitely not created in the first statement within main(). All that this statement does, is define a pointer 'a', to class zzz. But as soon as we say 'new zzz;', this array is created, and the starting location of this array is placed in a two byte pointer, just before the location where the variables start in memory. We do not even need to initialise 'a', for the array to be created. In other words, new is responsible for the creation of this array. Object 'a' comes into picture only when we have to call a function in the class.
Since the contents of this array points only to the virtual functions in the class, the array is known as a Virtual Table.
Let us take the case of a function being called. Let us assume that we have to call function pqr. We shall do this by saying ' a->pqr(); '. For the time being, let's assume that function pqr is not virtual. When the program is compiled, the functions will be left as they are, in the resultant obj file. Information as to where the functions are placed, will be given to the linker by the compiler. When the linker takes over, it simply gets the code of the function pqr, and places it in the appropriate location. The function is now ready for execution.
But if function pqr is virtual, the C++ compiler will first ask for the location where the object 'a' starts in memory. In the figure above, we have given this location as 500. This is also the location of the two-byte pointer, that contains the starting address of an array of pointers. The C++ compiler obtains this address by saying ' * 500 '. The answer it gets is 550, the start of the Virtual Table. It then jumps to this address. The C++ compiler further finds out whether the function pqr is the first, second or the third virtual function. Since pqr is the second virtual function, it skips the first four bytes and jumps to location 554. It obtains the contents of this memory location. It turns out that, at this location, the number 620 is present. This is the address of the function pqr. The code of this function will now get executed at runtime.
th5.cpp:
#include <stdio.h>
class zzz
{
public:
int i,j,k;
virtual void abc()
{ printf("In zzz abc");}
virtual void pqr()
{ printf("In zzz pqr");}
virtual void xyz()
{ printf("In zzz xyz");}
};
main()
{
zzz *a;
a = new zzz;
a->pqr();
}
OUTPUT:
In zzz pqr
This concept of introducing a virtual table as an imtermediate stage slows down the entire execution process, because now the function has to be accessed in a very round-about manner. The addresses of a function, however, remains the same, whether it is virtual or not.
We now consider the case of a class derived from class zzz.
th6.cpp:
#include <stdio.h>
class zzz
{
public:
int i,j,k;
virtual void abc()
{ printf("In zzz abc");}
virtual void pqr()
{ printf("In zzz pqr");}
virtual void xyz()
{ printf("In zzz xyz");}
};
class yyy:public zzz
{
public:
virtual void abc()
{ printf("In yyy abc");}
virtual void pqr()
{ printf("In yyy pqr");}
virtual void aaa()
{ printf("In yyy aaa");}
};
main()
{
zzz *a = new zzz;
a->abc();
}
The explanation of this program has already been given, earlier. We have defined 'a' as a pointer to zzz, when we said ' zzz *a', and it has also initialised to zzz, when we equated 'a' to 'new zzz'. Therefore, function abc gets called from class zzz only. But, suppose we rewrite main(), so that 'a' is initialised to class yyy, keeping the rest of the program same, what difference does this make ?
main()
{
zzz *a = new yyy;
a->abc();
}
Function abc is virtual in class zzz. As class yyy is derived from class zzz, abc automatically becomes virtual in class yyy. It does not matter what we define 'a' to. As soon as we say 'new yyy',an array of pointers is created in memory. The addresses that go into this array are of the functions of the class to which we have said 'new' to. Thus, the virtual table contains the addresses of virtual functions of class yyy. The sequence in which these functions are placed in the array, however, depend on class zzz. This is because class zzz is the base class. This means that the ordering of the functions in the virtual table is decided by the base class, but the functions that get called, are the functions belonging to the derived class. Because the ordering is decided by the base class, then functions that appear first in the virtual table are the functions in class zzz, namely functions abc, pqr and xyz. Following this, any virtual functions that are only present in class yyy will be placed, for example function aaa. Even though the virtual functions of class zzz are the ones placed in the virtual table, when any of those functions have to be called, they are called from class yyy. When function abc is called, it absolutely doesn't matter whether 'a' is defined as a pointer to class zzz or to class yyy. The virtual function, abc, will always be called from the class, to which we have said 'new', that is, class yyy in this example.


Once again, take a look at the second line in main(), that is 'zzz *a = new yyy;'. We repeat our earlier statement, that it really doesn't matter what's on the left-hand side of the equal-to sign. If we have said 'new yyy', then C++ will not check to see whether 'a' is a pointer to class zzz or to class yyy. C++ will check to see whether it's rules are being met or not. It makes sure that we don't have a larger class on the left-hand side and a smaller class on the right-hand side. It will, as far as possible, call the function from class yyy, because class yyy is the class on the right-hand side of the equal-to sign. However, if a function is not present in class yyy, it will be called from class zzz. This is what happens when the function xyz() has to be called. A check is done only if we have to call the function aaa(). This function is not present in class zzz, the class which 'a' has been defined as a pointer to. In this case, trying to call function aaa() will result in an error.
However, if we define 'a' as a pointer to class yyy, by saying ' yyy *a = new yyy; ' we have absolutely no problems. We can call any of the four functions in the figure above. The way function pqr is called is exactly as described for the previous figure.
But let's go back to defining 'a' to be a pointer to class zzz, but initialising it to class yyy. The function abc will be called from the class we have initialised 'a' to. Thus, we are calling code from a higher class, using a pointer to a smaller class. This is a true representation of polymorphic behaviour.
Is it possible for us to make a function without any code, in a class, equal to zero ? Let us take the case of an ordinary C++ program, with a single function, abc, to test this out.
vz1.cpp:
class zzz
{
public:
void abc( )=0;
};
main( )
{
zzz *a;
}
I suppose, we all may have expected errors from this program. After all, who's ever heard of a function being made equal to zero ? We do get a single error saying 'Non-virtual function zzz::abc declared pure'. Even if we don't understand what this actually means, we can infer that we aren't able to equate function abc to zero. It's quite useless trying to initialise 'a' in main( ), with the statement ' a = new zzz; ' . We only get an additional error saying that we cannot create an instance of abstract class zzz, another meaningless error. An instance of a class refers to an object of the class. Thus we cannot create an object of our class zzz.
But what if we make the function virtual, and than make it equal to zero ?
vz2.cpp:
class zzz
{
public:
virtual void abc( )=0;
};
main( )
{
zzz *a;
}
To our delight, it doesn't give us any errors. But before we jump for joy, let's remind ourselves that we have only created a pointer to class zzz. An object of class zzz hasn't yet been created. This object is created when we say new zzz.
vz3.cpp:
class zzz
{
public:
virtual void abc( )=0;
};
main( )
{
zzz *a;
a = new zzz;
}
Well, our luck had to run out sometime. We still get an error. An error that tells us we cannot create an object of class zzz.
vz4.cpp:
class zzz
{
public:
virtual void abc( )=0;
};
class yyy:public zzz
{
public:
}
main( )
{
yyy *a;
a = new yyy;
}
The above program seems to be a totally useless exercise. We have derived a class yyy from class zzz. We can hardly expect to create an object of the derived class, yyy, when we couldn't couldn't create an object of the base class, zzz.
In our next program, we have added the name of the function, abc( ), along with a pair of braces within class yyy. In other words, we have the entire code of function abc( ) in class yyy.
vz5.cpp:
class zzz
{
public:
virtual void abc( )=0;
};
class yyy:public zzz
{
public:
void abc( ){ }
}
main( )
{
yyy *a;
a = new yyy;
}
To our surprise, this program gives us absolutely no errors. If you ask me, the entire sequence of programs make no sense. We couldn't create an object of class zzz, a class that contains a virtual function abc( ), which we equated to zero. We couldn't create an object of class yyy, which was derived from class zzz, either. But the moment we added the code of function abc, we get no errors.
This could only mean one thing. When we have made a virtual function abc( ), without code, equal to zero, in class zzz, we cannot create an object of that class. Now, when we derive a class yyy, from this class zzz, the entire code of the function, abc, has to be added to class yyy. By entire code, we mean that the function should have the name, the parameters, as well as the return values of the function, as in the base class. If class zzz had to have a number of functions that were virtual as well as equal to zero, we would have to add the code of all these functions in class yyy. Then only, can we create an object of the class yyy.
If we had virtual functions in class zzz, either equated to zero, or not equated to zero, a Virtual Table gets created. Now if we derive another class, yyy, from class zzz, all the functions automatically come into class yyy, as long as the virtual functions in class zzz weren't equated to zero. But if class zzz contained a virtual function equal to zero, we are forced to include the code of that function in class yyy. Thus, making a virtual function equal to zero in a class, guarantees us that any class derived from this class will have to implement this function. The ordering of the Virtual Table will always be decided by the base class. In other words, class zzz will decide the order in which all virtual functions are called, in class yyy. This doesn't change, irrespective of whether the virtual functions are equal to zero, or not equal to zero, in class zzz.
We finally consider the case of a class xxx, which has been derived from class yyy, which is, in turn, derived from class zzz. Both, class zzz as well as class yyy, have one virtual function equal to zero, each.
vz6.cpp:
class zzz
{
public:
virtual void abc()=0;
};
class yyy:public zzz
{
public:
virtual void pqr()=0;
} ;
class xxx:public yyy
{
public:
void abc(){}
void pqr(){}
};
main()
{
xxx *a;
a=new xxx;
}
We are now forced to have the code of both, function pqr as well as function abc, in class xxx. Class xxx is actually derived from class zzz and class yyy. If there are any virtual functions that are equated to zero in any of these two classes, then we have to have the code of these functions in class xxx.
Reference Operators
We are firm believers in the fact that, in order to learn new technologies, we need to get our basics rights. Let us take the case where we have to pass a number of parameters to a function. For the moment, we pass only two parameters to a function, abc. Within the function abc, we have an additional variable, k. We use this variable to temporarily store the value of i. We then assign the value of j to i, and the value of k to j. In other words, we have exchanged the values of i and j, in the function, abc.
ref1.cpp:
#include<stdio.h>
void abc(int ,int );
main()
{
int i,j;
i=10;
j=20;
abc( i, j );
printf("i=%d..j=%d \n",i,j);
}
void abc(int i, int j)
{
int k;
k=i;
i=j;
j=k;
}
OUTPUT:
i=10..j=20
Within main(), the variables i and j have the values, 10 and 20, respectively. In the line ' abc( i, j ); ', these values of i and j are put on the stack. The value of j goes on the stack first, followed by the value of i. This is as shown in the figure below. Only then, is the function abc is called.
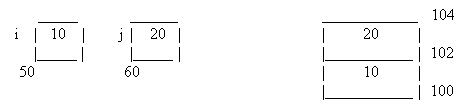
When function abc is called, it picks up the values in reverse order, that is, i is picked up first, followed by j. Within function abc, the values of i and j are interchanged, with the help of k. So now, the value of i is 20, and that of j is10. This change is visible in the values on the stack. This change in i and j is however, restricted to the function abc. If we display the addresses of i and j in the function abc, we shall see that they are different from the addresses of i and j in main(). In no way do changes made to i and j in abc() affect the values of i and j within main(). This is because at the end of the statement 'abc();' within main(), the stack is restored to point to 104 by main(), as soon as the ';' is encountered. By this, we mean that if the stack moved four locations down at the beginning of the function call, main() moves it four locations up after the function has been executed. When the function printf() is called, the values of i and j that go on the stack, are those values that are within main(). This is why, printf will display the values of i and j as 10 and 20.
Suppose we want any change made to variables within a function to be visible within main(), we have to make use of pointers. Instead of putting the values of the variables on the stack, we put their addresses on the stack. This is shown in the next program.
ref2.cpp:
#include<stdio.h>
void abc(int *,int *);
main()
{
int i,j;
i=10;
j=20;
abc(&i,&j);
printf("i=%d...j=%d \n",i,j);
}
void abc(int *i, int *j)
{
int k;
k=*i;
*i=*j;
*j=k;
}
OUTPUT:
i=20...j=10
Within main(), we now have the line ' abc(int &i, int &j); '. Therefore, when the function abc is called from main, the stack is as shown in the figure. The addresses of the variables, i and j, are obtained from the previous figure.
The function will accept the addresses of the two variables from the stack. As in the previous program, we have an intermediate variable, k, which we use when exchanging the values of i and j. However, everytime we have to access the values of the two variables, we have to use *i and *j. When we change the value of *i, we are effectively changing the value of the variable that is at memory location 50. Thus any change in the function is reflected within main().
If we wish to utilise these variables a number of times in our function, we not only have to make quite a few changes from the previous program, ref1.cpp, but in general, we also create a lot of confusion.
Is there a method by which we could have any changes to the values of variables within a function, visible within main(), but without making major changes to the code within the function?
Let us look at the next example.
ref3.cpp:
#include<stdio.h>
void abc(int &,int &);
main()
{
int i,j;
i=10;
j=20;
abc(i,j);
printf("i=%d...j=%d \n",i,j);
}
void abc(int &i, int &j)
{
int k;
k=i;
i=j;
j=k;
}
OUTPUT:
i=20...j=10
Consider the above program and compare it with our first program, ref1.cpp. We have changed the prototype of function abc at the top of this program. The variables that we now pass are 'int &' instead of just 'int'. The actual function name has to follow the same pattern as the prototype. We have made corresponding changes here as well. We haven't, however, made any changes in the code of the function abc. From main( ), the function abc is called in the same way, as in ref1.cpp.
As in that program, we also exchanged the values of i and j, without using *i and *j. We find that printf() in main() displays the new values of i and j.
We changed the prototype of the function, so that the parameters of the function are 'int &' instead of only 'int'. When we call function abc, we retain the statement ' abc(a,b); '. But what goes on the stack are not the values of i and j. Because of the prototype, what actually goes on the stack are the addresses of i and j. The function abc now gets these addresses. But the code of this function does not have pointers to access the values at these addresses. C++ therefore goes and writes *i and *j, where ever it sees i and j in function abc. We arrive at the conclusion that when you see & in the prototype and name of the function, pretend that you haven't seen the &, and write the code of the function accordingly. This programs now works in exactly the same way as ref2.cpp.
ref4.cpp:
#include<stdio.h>
struct zzz
{
int i,j,k;
};
abc(struct zzz );
main()
{
struct zzz a;
a.i=1;
a.j=2;
a.k=3;
abc(a);
printf("a.i=%d...a.j=%d...a.k=%d",a.i,a.j,a.k);
}
abc(struct zzz z)
{
z.i=10;
z.j=20;
z.k=30;
}
OUTPUT:
a.i=1...a.j=2...a.k=3
In this program, we have a structure 'a', whose members have been initialised within main( ). When we say ' abc(a); ', the entire structure goes on stack. The variables of this structure have been given new values within the function. But changing their values in the function has no effect on the values of the variables within main(). The original values within main( ) are displayed by printf(). As usual, if we wish to have changes made to the variables in a function, visible within main(), we are, once again forced to use pointers.
ref5.cpp:
#include<stdio.h>
struct zzz
{
int i,j,k;
};
abc(struct zzz *);
main()
{
struct zzz a;
a.i=1;
a.j=2;
a.k=3;
abc(&a);
printf("a.i=%d...a.j=%d...a.k=%d",a.i,a.j,a.k);
}
abc(struct zzz *z)
{
z->i=10;
z->j=20;
z->k=30;
}
OUTPUT:
a.i=10...a.j=20...a.k=30
In this program, when the function abc is called, we do not pass the entire structure. Only the address of where the structure starts in memory is passed. Passing an address is especially useful when we have an extremely large structure. For example, if the structure occupied 30 memory locations, what would go on the stack would still be four memory locations that made up the address.
This address is now accepted by a parameter of function abc, which has to be a pointer. Because it is a pointer, corresponding changes have to be made in the code of the function. We can no longer refer to the members of the structure as we did in program ref4.cpp. Thus, instead of saying 'a.i', we are forced to say a->i, every time we have to access i. This means that major changes have to be made in the code of the function.
ref6.cpp
:#include<stdio.h>
struct zzz
{
int i,j,k;
};
abc(struct zzz &);
main()
{
struct zzz a;
a.i=1;
a.j=2;
a.k=3;
abc(a);
printf("a.i=%d...a.j=%d...a.k=%d",a.i,a.j,a.k);
}
abc(struct zzz &z)
{
z.i=10;
z.j=20;
z.k=30;
}
OUTPUT:
a.i=10...a.j=20...a.k=30
Compared to program ref4.cpp, the only change that we have made is to rewrite the prototype of function abc as abc(struct zzz &) instead of abc(struct zzz). We have called function abc in exactly the same manner as we did in program ref4.cpp, by saying 'abc(a);'. However, the entire structure does not go on the stack. Because of the prototype, only the address of structure 'a' goes on the stack.
The format of the function abc is the same as it's prototype. The parameter of abc accepts this address. We do not, however, have to rewrite our code, within the function. When C++ sees ' z.i ', it automatically rewrites it as ' z->i '. Any change we now make to the variables of function abc will be visible within main( ).
When we initially write the code of a function, we often do not use pointers initially, as using pointers can make the code more complicated. It is only when we have to optimise the code for both speed and memory space, that we rewrite the code to make use of pointers. But with C++, we only make changes to the prototype and the function name with no changes to the actual code. By the mere insertion of an &, our code is rewritten and works as if the variables were pointers.
So if you see an & in front of a parameter of a function, tell yourself that you haven't seen it at all, when you write the code of your function.
By Default
...Consider the following program. The prototype of the function abc tells us that the function abc accepts two integers. When we run this program, the two values we called function abc with are displayed.
dfc1.cpp:
#include<stdio.h>
int abc(int, int);
main()
{
abc(10,20);
}
int abc(int i, int j)
{
printf("i=%d...j=%d\n",i,j);
}
OUTPUT:
i=10...j=20
Let us modify main() to include an additional call to the same function abc. Now, however, we try to call abc with only one parameter, keeping the rest of the program unchanged.
dfc2.cpp:
#include<stdio.h>
int abc(int, int);
main()
{
abc(10,20);
abc(100);
}
int abc(int i, int j)
{
printf("i=%d...j=%d\n",i,j);
}
We obviously get an error informing us that a call to function abc is being made with too few parameters. We could write an additional function that accepts only one int. Let us assume for the moment that we do not want to write an additional function, but wish to call the same function. A solution to this problem is shown in the next program.
dfc3.cpp:
#include<stdio.h>
int abc(int i, int j=5);
main()
{
abc(10,20);
abc(100);
}
int abc(int i, int j)
{
printf("i=%d...j=%d\n",i,j);
}
OUTPUT:
i=10...j=20 i=100...j=5
Our program code has remained absolutely same, and we still call function abc with one parameter, only. The only change that we have made, is in the prototype of the function. We have initialised the second parameter in the prototype to 5. When function abc is now called with only one parameter, the other parameter is automatically inserted by the C++ compiler, from the prototype. To be more specific, when we say ' abc(100); ' within main( ), it implies that we are actually calling function abc with two parameters, 100 and 5. The first parameter, 100, is visible to us in the call to the function, itself. The second parameter is the value present in the prototype. Since we haven't actually given a second parameter in ' abc(100); ', the value present in the prototype is accepted as the second parameter, by default. The second call to the function will appear to C++ as
' abc(100,5); '.
If we call a function with two integers, as it should be called, these are the values that are displayed. Giving a default value in the prototype has no effect in this case.
In the program above, we called a function that accepts two parameters, with only one parameter. The function is called with a default value as the second parameter, that is present in the prototype. In the next program, we once again, call function abc with one parameter. But instead of initialising the second parameter in the prototype, we initialise the first parameter.
dfc4.cpp:
#include<stdio.h>
int abc(int i=4, int j);
main()
{
abc(100);
}
int abc(int i, int j)
{
printf("i=%d...j=%d\n",i,j);
}
Error!Error! We don't get just a single error. We had to get two errors. The first error says 'Default value missing following parameter i ' while the second error is the same as an earlier error 'Too few parameters in call to function abc'. But how was this program so different from program def3.cpp. In that program also, we had called function abc with one parameter only. The parameter we placed in the prototype was taken as the second parameter.
The problem is that when a function accepts default parameters from a prototype, default parameters can only be accepted from the last parameter, backwards. Thus if a function has five parameters, and we have initialised the last three parameters in the prototype, we are allowed to call the function with only two parameters. The values we give in the actual call to the function will be accepted as the first two parameters, with the last three values being obtained from the prototype. But there is no way we can initialise the first three parameters in a prototype, and expect the two values in the call to the function to initialise the last two parameters.
In program dfc4.cpp, we do not have the right to tell the function that the first parameter is default and initialised in the prototype, while the second one is not. We are, ineffect, trying to call a function by saying abc( , 100), and expecting C++ to fill up the first parameter. C++ will not accept our trying to tell it that, since we already have the first parameter initialised in the prototype, the value we have placed in the call to the function should become the second parameter. We shall definitely get an error.
Suppose we had initialised both the parameters of function abc in the prototype, itself, we don't need to give any parameters while calling function abc.
dfc5.cpp:
#include<stdio.h>
int abc(int i=4, int j=5);
main()
{
abc(10,20);
abc();
}
int abc(int i, int j)
{
printf("i=%d...j=%d\n",i,j);
}
OUTPUT:
i=10...j=20 i=4...j=5
Take a look at the next program. Here, we have two prototypes of the function named abc, the first prototype with two parameters, and the second with one parameter. The second parameter of the first prototype has been initialised to some value. We also have the code of both the functions in the program.
dfc6.cpp:
#include<stdio.h>
int abc(int i, int j=5);
int abc(int i);
main()
{
abc(10,20);
abc(100);
}
int abc(int i, int j)
{
printf("i=%d...j=%d\n",i,j);
}
int abc(int i)
{
printf("i=%d",i);
}
When we compile this program, we get an error saying ' ambiguity between function abc(int, int) and abc(int) '. At the line ' abc(100); ' , the C++ compiler does not know whether we are trying to call function abc with one parameter, or the function abc with two parameters. If it has to call the function abc which has one parameter, it has to pass only 100. But for the same statement 'abc(100);', if C++ has to call the function abc which has two parameters, a default value present in the prototype has to be inserted as the second parameter. Technically, both cases are possible. But since C++ does not know what option to take, it gives us an error.
dfc7.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x,int y)
{
i=x;
j=y;
printf("In constructor..i=%d..j=%d\n",i,j);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
a.print();
b.print();
}
OUTPUT:
In constructor..i=1..j=1 In constructor..i=2..j=2 In print i=1..j=1 In print i=2..j=2
Here, class zzz has a constructor with two parameters. When we say either ' zzz a(1,1); ' or we say ' zzz b(2,2); ' we are not only creating an object, but we are also calling this constructor. The values we call the constructor with, are assigned to i and j in the constructor. We have displayed these values in the constructor, and they are also displayed by the function print().
Take a look at the next program. We have to ask ourselves a few questions. We appear to be creating an object 'c' of class zzz, and initialising this object to another object, 'a'. Will the constructor be called by the statement ' zzz c = a ; ' ? We haven't passed any parameters with 'c', so what will the function print() display ?
ini1.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=10,int y=20)
{
i=x;
j=y;
printf("In constructor..i=%d..j=%d\n",i,j);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c = a;
a.print();
b.print();
c.print();
}
OUTPUT:
In constructor..i=1..j=1 In constructor..i=2..j=2 In print i=1..j=1 In print i=2..j=2 In print i=1..j=1
We are allowed to initialise our object 'c' only to another object that is similar to it. Here, we have initialised it to object 'a'.
We notice, from the output that the constructor is called by 'a' and by 'b', but not by 'c'. However, when we say ' c.print(); ', the values that are displayed are the parameters we have passed when we created object 'a'.
Whenever we create an object, a constructor has to be called. But if we are creating an object and initialising it at the same time, the type of constructor that we have in the above program doesn't get called.
We now introduce one more type of constructor. To this constructor, we pass the address of an object of the current class, by reference. In other words, the object does not go on the stack, only the address of the object goes on the stack. This address is accepted by the constructor.
ini2.cpp:
#include<stdio.h>
class zzz
{
public:
int i , j;
zzz(int x=10,int y=20)
{
i = x;
j = y;
printf("In constructor1..i=%d..j=%d\n",i,j);
}
zzz( zzz &z)
{
printf("In constructor2..i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c=a;
a.print();
b.print();
c.print();
}
OUTPUT:
In constructor1..i=1..j=1 In constructor1..i=2..j=2 In constructor2..i=970..j=964..z.i=1..z.j=1 In print i=1..j=1 In print i=2..j=2 In print i=970..j=964
We have two constructors in this program. The first one is called with two ints, while the second is passed the address of an object of the class. In our program we have the line 'zzz c=a;'. Thus we have created an object 'c' and initialised it to 'a'. Since we have passed an object 'a' to the second constructor, z.i and z.j in this constructor will be the values of a.i and a.j, respectively. However, since the values of i and j haven't been initialised, we cannot predict what their values will be. The values of i and j in the second constructor, will also be the values of i and j that c.print() will display.
The second constructor is called the initialisation constructor. It gets called whenever we create an object, and initialise it at the same time.
ini3.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=10,int y=20)
{
i=x; j=y;
printf("In constructor1..i=%d..j=%d\n",i,j);
}
zzz(zzz &z)
{
printf("In constructor2..i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
i=z.i; j=z.j;
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c=a;
a.print();
b.print();
c.print();
}
OUTPUT:
In constructor1..i=1..j=1 In constructor1..i=2..j=2 In constructor2..i=970..j=964..z.i=1..z.j=1 In print i=1..j=1 In print i=2..j=2 In print i=1..j=1
The only change we have made out here is to initialise the variables, i and j, in the initialisation constructor. But since we have initialised these values after the printf() within the constructor, the values of i and j displayed from the initialisation constructor will be any arbitary values. The output of c.print() now displays the values of i and j as 1 and 1.
ini4.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=10,int y=20)
{
i=x; j=y;
printf("In constructor1..i=%d..j=%d\n",i,j);
}
zzz(zzz &z)
{
printf("In constructor2..i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
this->i=z.i;
this->j=z.j;
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c=a;
a.print();
b.print();
c.print();
}
OUTPUT:
In constructor..i=1..j=1 In constructor1..i=2..j=2 In constructor2..i=970..j=964..z.i=1..z.j=1 In print i=1..j=1 In print i=2..j=2 In print i=1..j=1
Sometimes, the only way to get a true understanding of a program, is to try and replicate what C++ does internally. Basically, when a function in a class gets called, it doesn't know which object is calling it. It simply looks at the where the stack points to. Much earlier, in this tutorial we had mentioned that when a function gets called, C++ creates a pointer to the current class. C++ then inserts the pointer it created, as the first parameter of the function. The pointer is known as the 'this' pointer.
The 'this' pointer points to the current object. Thus the function is able to know which object is calling it. A constructor is also a function, like any other, except for the manner in which it can be called. The constructor also will have a 'this' pointer as the first parameter. Through the eyes of C++, the initialisation constructor will look like
zzz( zzz *this, zzz &z){}. When we say ' zzz c = a; ', the initialisation constructor gets called. Here, since the initialisation constructor is called by the object 'c', the 'this' pointer will point to where 'c' starts in memory. This location is where the variables of the object 'c' are located. The variables of the object 'c' are now accessed by the 'this' pointer by saying this->i and this->j. Logically, this->i and this->j are the same as c.i and c.j. The fact that the address of 'this' and the address of c are the same is shown in the next program.
ini5.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=10,int y=20)
{
i=x; j=y;
printf("In constructor1..i=%d..j=%d\n",i,j);
}
zzz(zzz &z)
{
printf("In constructor2..i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
this->i=z.i;
this->j=z.j;
printf("Addr of this %p\n",this);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c=a;
a.print();
b.print();
c.print();
printf("Addr of c %p",&c);
}
OUTPUT:
In constructor1..i=1..j=1 In constructor1..i=2..j=2 In constructor2..i=1002..j=996..z.i=1..z.j=1 Addr of this 10FC:0FF4 In print i=1..j=1 In print i=2..j=2 In print i=1..j=1 Addr of c 10FC:0FF4
The values of c.i and c.j become 1,1 due to the initialisation constructor. We shall explain how the entire initialisation process takes place in great detail later on.
ini6.cpp:
#include<stdio.h>
class zzz
{ public:
int i,j;
zzz(int x=10,int y=20)
{
i=x; j=y;
printf("In constructor1..i=%d..j=%d\n",i,j);
}
zzz(zzz &z)
{
i=z.i; j=z.j;
printf("In constructor2..i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
}
void abc()
{
printf("In abc..%d..%d\n",i,j);
i=10; j=20;
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);}
};
main()
{
zzz a(1,1);
zzz b(2,2);
a.print();
b.print();
a.abc();
a.print();
}
OUTPUT:
In constructor1..i=1..j=1 In constructor1..i=2..j=2 In print i=1..j=1 In print i=2..j=2 In abc..1..1 In print i=10..j=20
When we see the line ' a.abc(); ' within main(), we know that we are calling a function from our class. Therefore, somewhere in the class, we should have a function
' void abc(){}'. Within function abc, we are displaying the values of i and j. Since this function is being called by 'a', the values of i and j will obviously be those of 'a'. Within function abc, if we initialise i and j to 10 and 20, these values will be displayed when we say ' a.print(); '.
In our next program, we replace a.abc() within main(), with a call to a function pqr. This function is passed a parameter, 'b'. If we take a look at our previous statements, we shall find that 'b' is an object of class zzz. So, the function pqr(), within class zzz also has to be written to be able to accept an object of class zzz. It will now have to look like
' pqr(zzz zz){} '.
ini7.cpp:
#include<stdio.h>
class zzz
{ public:
int i,j;
zzz(int x=10,int y=20)
{
i=x; j=y;
printf("In constructor1..i=%d..j=%d\n",i,j);
}
zzz(zzz &z)
{
printf("In constructor2..i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
i=z.i; j=z.j;
}
void pqr(zzz zz)
{
printf("In pqr..%d..%d..%d..%d\n",i,j,zz.i,zz.j);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);}
};
main()
{
zzz a(1,1);
zzz b(2,2);
a.print();
b.print();
a.pqr(b);
}
OUTPUT:
In constructor1..i=1..j=1 In constructor1..i=2..j=2 In print i=1..j=1 In print i=2..j=2 In constructor2..i=4088..j=4348..z.i=2..z.j=2 In pqr..1..1..2..2
When we say ' a.pqr(b); ', we are calling function pqr, in class zzz, and passing an object 'b' to this function. Function pqr has a parameter 'zz', that is an object of class zzz. At the instant at which function pqr is called, this object 'zz' is created and it's members are assigned the values of b.i and b.j. Thus, we are actually creating an object and initialising it at the same time. This initialisation is done by the initialisation constructor. This is why we see the output of printf() in the initialisation constructor, before we see the output of printf() in function pqr(). Since we have passed the object 'b' to the function pqr, in the initialisation constructor, z.i and z.j have to be equal to b.i and b.j. As in the previous example, in function pqr, i and j will be the values of a.i and a.j.
Let us go a bit deeper into initialisation constructors. There are two types of statements by which we can create an object and initialise it at the same time. The first statement is of type ' zzz c = a; ', while the second statement is of type ' a.pqr( b ); '. In both cases,the initialisation constructor is called.
Whenever we have a class, for example, class zzz{ public:}, C++ first looks at whether we have a constructor or not. If we do not, C++ inserts a constructor which takes no parameters, zzz(){}, into our class. After this, the C++ compiler also looks to see if we have an initialisation constructor within our class. If we don't, C++ inserts an initialisation constructor, as well. This constructor looks like
zzz(zzz &z)
{
i = z.i; j =z.j; ...
}
The number of variables that the object 'z' has, is not fixed. It depends on the object being passed to the constructor. Consider the second case, that is ' a.pqr( b ); '. Here, we are passing the object 'b' to function pqr. The object 'b' was created with two parameters. Therefore, the number of variables that are created and initialised within the constructor will be two. If 'b' had to have four parameters, 'z' would also have four variables.
Now look at the program ini1.cpp. Here, we have the first case when an initialisation constructor is called, that is ' zzz c = a; '. We do not have our own initialisation constructor in this program. C++ will insert a default initialisation constructor. We are creating an object 'c' and initialising it to look like an object 'a'. Since the object 'a' was created with two parameters, the object 'c' will also have two parameters. Now, c.print() will display the variables i and j as the vallues of a.i and a.j.
If we, however, insert our own initialisation constructor, we have to initialise i and j to a.i and a.j, respectively.
But, let's get back to program ini7.cpp. When our program is being executed, C++ encounters the line ' a.pqr(b); ', it will call function pqr. Function pqr appears to C++ as ' pqr(zzz *this, zzz zz){}'. So when function pqr is called, the parameters go on the stack in the reverse order. The first thing to go on the stack is an object of class zzz. Since class zzz has two integers, two memory locations are reserved for each of them. Another four bytes are taken up by the 'this' pointer. Let us assume that the objects, 'a' and 'b' lie at 1000 and 2000 respectively. Since the current object calling function pqr is 'a', the 'this' pointer points to 'a'. The stack of function pqr is as shown in the figure below.
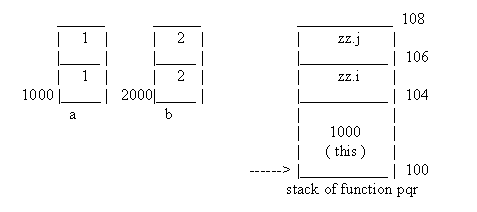
We know that function pqr is passed an object 'b'. The parameter of function pqr that has to accept object 'b', is the object zz. We have also stated that memory has been reserved for the variables of the object zz. But we haven't said anything about who is responsible for initialising these variables.
The responsibility of initialising the variables of zz to b.i and b.j, lies in the hands of the initialisation constructor. As soon as memory is allocated for the variables of zz and the 'this' pointer is filled up, control of the stack is transferred to the initialisation constructor.
Suppose the stack of the initialisation constructor is at 208. Internally, the initialisation constructor looks like zzz(zzz *this, zzz &z){}.
Now zz.i and zz.j in function pqr have to be initialised to the values of b.i and b.j. Therefore, the address of 'b' has to be passed to the initialisation constructor. This is the first parameter that goes on the stack. The second parameter that goes on the stack is the 'this' pointer.

stack of the initialisation constructor
The initialisation constructor is actually called when we say 'zzz zz' as the parameter of function pqr. Therefore the address of the 'this' pointer in the initialisation constructor is that of the object zz. From the previous figure, we see that zz lies at 104.
Now zz.i and zz.j in function pqr have to be initialised to the values of b.i and b.j. In the initialisation constructor, 'z' has the address of 'b'. So, when we have the statements 'i = z.i;' and 'j = z.j;' , what we are actually doing by these statements, is saying '104->i = b.i;' and ' 104->j = b.j;'. Thus, the values of zz.i and zz.j in function pqr get filled up.
Now, consider the case when we have a slight modification to the function pqr in the previous program.
ini8.cpp:
#include<stdio.h>
class zzz
{ public:
int i,j;
zzz(int x=10,int y=20)
{
i=x; j=y;
printf("In constructor1..i=%d..j=%d\n",i,j);
}
zzz(zzz &z)
{
printf("In constructor2..i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
i=z.i; j=z.j;
}
void pqr(zzz &zz)
{
printf("In pqr..%d..%d..%d..%d\n",i,j,zz.i,zz.j);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);}
};
main()
{
zzz a(1,1);
zzz b(2,2);
a.print();
b.print();
a.pqr(b);
}
OUTPUT:
In constructor1..i=1..j=1 In constructor1..i=2..j=2 In print i=1..j=1 In print i=2..j=2 In pqr..1..1..2..2
In this program, function pqr has a parameter that is passed to it by reference. Instead of saying pqr(zzz zz){}, we are saying pqr(zzz &zz){}. Therefore zz is no longer an object, but a pointer to class zzz. When we call function pqr, what goes on the stack is not an actual object , but only the address of an object that is being passed as a parameter to function pqr. The stack is as shown below. As no object is created, the initialisation constructor is not called.
Operator Overloading
Everything in C++ ultimately boils down to being either a class or an object. When we say ' int i, j; ', int is a class while i and j are objects of the class. Statements like 'i + j;' are perfectly valid. However, it should be noted that 'int', 'long' and so on are classes that belong to C++ and are actually inherited from the C programming language. So if we create our own class, and have two objects of the class, are we able to add or substract them, as if they were two ints ? In other words, are we able to add two objects of a user-defined class.
opo1.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=0,int y=0)
{
i=x; j=y;
printf("In constr %d.. %d\n",i,j);
}
void print()
{
printf("%d..%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c(3,3);
b+c;
}
If the line 'b+c;' wasn't there, the constructor would be called thrice, when this program was executed. At the line ' b + c; ', we get an error telling us that we have performed an illegal structure operation. So maybe, we can't add two objects in the normal way. That doesn't mean that we can't add two objects at all. Let us look at why we got an error in the first place. The '+' is an operator. It doesn't understand a zzz on the left and a zzz on the right, as zzz represents our own class.
Suppose there was a way by means of which we could manipulate the statement ' b+c; ', so that it perform the same tasks as the statement ' b. + ( c ); ', our problems would be solved. Effectively, what we are trying to do, is make '+' act like a function. This function has a parameter 'c', which is an object. The function is called by another object 'b'. Of course, the statement ' b. + ( c ); ' is not a valid statement. But, understanding this concept is essential to understand the next program.
opo2.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=0,int y=0)
{
i=x; j=y;
printf("In constr i=%d.. j=%d\n",i,j);
}
void operator + (zzz z)
{
printf("Operator i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c(3,3);
b+c;
}
OUTPUT:
In constr i=1.. j=1 In constr i=2.. j=2 In constr i=3.. j=3 Operator i=2..j=2..z.i=3..z.j=3
The line ' b+c; ' no longer give us any errors. This is due to the fact that we added the function ' void operator + (zzz z){} ', to our program. Within this function, we have also displayed the values of i, j and z.i, z.j. We find that the values of i and j are those of 'b', while the values of z.i, z.j are those of 'c'. The '+' now acts as a function that accepts an object as a parameter, and can be called by another object.
We need something that will accept the result of the addition of the two objects, 'b' and 'c'. For this purpose, we shall use the third object 'a'. We shall use a function, print(), to display the variables of the object 'a'.
opo3.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=0,int y=0)
{
i=x; j=y;
printf("In constr i=%d.. j=%d\n",i,j);
}
void operator + (zzz z)
{
printf("Operator i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c(3,3);
a=b+c;
}
We get an error that says 'not an allowed type', at the line 'a = b + c; '. Let us take a look at our function ' void operator + (zzz z){} '. We have defined this function to be a void function. In other words, it returns nothing. Obviously, it cannot return the result of the addition of the two objects, 'b' and 'c'. Since the return value of the addition is an object of class zzz, we rewrite our function as 'zzz operator + (zzz z){}'. We also define an object 'd' of class zzz. The addition of i and z.i is assigned to d.i, while the addition of j and z.j is assigned to d.j. We now say 'return d;', because we have to return an object of class zzz. As we said earlier, i and j are the values of 'b' while z.i and z.j are the values of 'c'. Therefore, d.i and d.j should represent the values of the addition of the objects 'b' and 'c'. This can be confirmed by the output of the print function.
opo4.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=0,int y=0)
{
i=x; j=y;
printf("In constr i=%d.. j=%d\n",i,j);
}
zzz operator + (zzz z)
{
printf("Operator i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
zzz d;
d.i=i+z.i;
d.j=j+z.j;
return d;
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c(3,3);
a=b+c;
a.print();
}
OUTPUT:
In constr i=1.. j=1 In constr i=2.. j=2 In constr i=3.. j=3 Operator i=2..j=2..z.i=3..z.j=3 In constr i=0.. j=0 In print i=5...j=5
Let us explain the output in detail. The first three lines indicate that the constructor is called by 'a', 'b', and 'c'. After the three objects are created, we have the statement ' a = b + c; '. We first look at what is to the right of the equal-to sign. Since we cannot add two objects of our own class in the normal manner, we have to perform the addition in a round-about manner. We overload the '+' operator to behave in a manner that a function would behave. To distinguish it from a normal function, we write the word, operator, in front of '+', when we write the name of the function. The '+' is now overloaded to perform a number of tasks. For example, it can add two numbers as well as act as if it were a function of a class. When '+' is treated as a function, it is known as an overloaded operator function.
In this program, +( ) will be called as if it were a function of the class zzz, by any object of the class. We are calling the operator overloaded function, ' +( ) ', from the object 'b'. We are passing this function, '+( )' , a single parameter 'c', that is also an object of class zzz. In the function, z accepts the values of the object 'c'. Therefore z.i and z.j display the values of c.i and c.j. Within this function, the values of i and j are equal to the values of b.i and b.j. We further create an object 'd', due to which the constructor is called with default values. The output of the addition of i and z.i is given to d.i, while that of j and z.j is given to d.j. Effectively, these values represent the addition of the objects 'b' and 'c'.
Let us extend whatever we have learned about overloading the '+' operator a bit further. We shall now add three objects and store their the result of their addition in a fourth object.
opo5.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=0,int y=0)
{
i=x; j=y;
printf("In constructor i=%d...j=%d\n",i,j);
}
zzz operator + (zzz z)
{
printf("Operator i=%d...j=%d...z.i=%d...z.j=%d\n",i,j,z.i,z.j);
zzz e;
e.i=i+z.i;
e.j=j+z.j;
return e;
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c(3,3);
zzz d(4,4);
a=b+c+d;
a.print();
}
When we add b.i, c.i and d.i, the resulting value will be 9. The same result is obtained when we add b.j, c.j and d.j. This can be confirmed from the last line of the output shown below.
In constructor i=1...j=1 In constructor i=2...j=2 In constructor i=3...j=3 In constructor i=4...j=4 Operator i=2...j=2...z.i=3...z.j=3 In constructor i=0...j=0 Operator i=5...j=5...z.i=4...z.j=4 In constructor i=0...j=0 In print i=9...j=9
The last line of the output fails to give us a true indication of what actually happens in the above program. To get the whole picture, we have to go through the entire output, line by line.
In the first four lines of the output, we see the constructors of the four objects being called.
After this, we come to the line ' a = b + c + d ; '. Do the objects, b, c and d get added, all at the same time, or do two objects get added first, after which the third gets added to obtain the final result ? To find out, read on.
In the very next line of the output, we see that the operator overloaded function has been called.When ' zzz operator + (zzz z){}' gets called, we see from the output that i and j are both equal to 2, while both z.i and z.j are 3. From this, we can conclude that only the first two objects are being added. What we mean is that only the addition of the b and c is being performed right now. As in the previous example, the operator overloaded function '+' is being called by the object 'b' with object 'c' as the parameter.
In the next line, the constructor is being called with default values, because within the operator overloading function, we have created an object 'e'. This object is used to return the result of the addition of the objects 'b' and 'c'. This primary result is then added to the object 'd'. The procedure followed is entirely the same. The object returned by ' b + c' now calls the operator overloaded function with object 'd' as the parameter. This can be confirmed, because in the output of printf() in the operator overloaded function, we can see that i and j are both 5, while z.i and z.j are both 4.
The constructor is called once again when C++ encounters 'zzz e;' in the operator overloaded function. Finally, the line ' a.print();' gives us the values of a.i and a.j after the addition of 'b', 'c' and 'd' as 9 and 9.
We now take a look at how other operators can be overloaded.
opo6.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=0,int y=0)
{
i=x; j=y;
printf("In constr i=%d..j= %d\n",i,j);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
a=b;
a.print();
}
OUTPUT:
In constr i=1..j=1 In constr i=2..j=2 In print i=2..j=2
We realise that when we say 'a=b;' , the value of the variables of a.i and a.j become equal to the values of b.i and b.j. This is quite unlike our first attempt at operator overloading, where we tried to add two objects. There, we obtained errors. But here, when we equate two objects, we have absolutely no problems. We therefore conclude that C++ has once again given us something free that enables us to equate two objects. That free thing would have to be an overloaded operator = function.
We just have to be thankful to C++ for being so considerate and making our lives so much easier. After all, it gives us a free constructor that takes no parameters, a free initialistion constructor, free 'this' pointers for every function, a free overloaded operator = function, and who knows, maybe a number of other freebees, as well.
For our own knowledge, we shall attempt to reproduce this operator overloaded = function that C++ gives us free of charge. As far as the general format of the function is concerned, it is the same as the overloaded '+' function.
opo7.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=0,int y=0)
{
i=x; j=y;
printf("In constr i=%d..j=%d\n",i,j);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
void operator = (zzz z)
{
printf("In = Operator i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
i=z.i;j=z.j;
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
a=b;
a.print();
}
OUTPUT:
In constr i=1.. j=1 In constr i=2.. j=2 In = Operator i=1..j=1..z.i=2..z.j=2 In print i=2..j=2
We can see that the final line of the output of this program is the same as that of the previous program. But, in between, we notice that the the overloaded = operator function has been called. Thus, when C++ comes across the line ' a = b; ', it assumes that 'a' is an object that is calling a function ' = ', and a single parameter 'b' is being passed to this function.
Lets remove our overloaded = operator function for the time-being, and try to equate three objects, that is, 'a = b = c '.
opo8.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=0,int y=0)
{
i=x; j=y;
printf("In constr i=%d..j= %d\n",i,j);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c(3,3);
a=b=c;
a.print();
}
OUTPUT:
In constr i=1..j=1 In constr i=2..j=2 In constr i=3..j=3 In print i=3..j=3
As we see, the program works perfectly. From the last line of the output, we can see that a.i and a.j have accquired the values of c.i and c.j. Of course, the only way we can figure out what happens internally, is to actually have our own overloaded = operator function perform exactly what C++ does. We now insert the same overloaded = operator function that we earlier had into our next program.
opo9.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=0,int y=0)
{
i=x; j=y;
printf("In constr %d.. %d\n",i,j);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
void operator = (zzz z)
{
printf("In Operator i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
i=z.i; j=z.j;
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c(3,3);
a=b=c;
a.print();
}
To our dismay , we get an error at the line 'a = b = c;', saying 'not an allowed type'.Serves us right. If we look back a few programs, we see that we got precisely the same error in program opo3.cpp. The error arises because when b=c is evaluated, the result is an object, that has to be returned by the overloaded = operator function . But the overloaded = operator function is a void function, and cannot return anything. We had solved the error in that example, by rewriting the overloaded operator function to return an object that looks like class zzz. Here too, we do the same thing.
opo10.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x=0,int y=0)
{
i=x; j=y;
printf("In constr %d.. %d\n",i,j);
}
void print()
{
printf("In print i=%d..j=%d\n",i,j);
}
zzz operator = (zzz z)
{
printf("In Operator i=%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
i=z.i;j=z.j;
return *this;
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
zzz c(3,3);
a=b=c;
a.print();
}
OUTPUT:
In constr 1.. 1 In constr 2.. 2 In constr 3.. 3 In Operator i=2..j=2..z.i=3..z.j=3 In Operator i=1..j=1..z.i=3..z.j=3 In print i=3..j=3
The program now gives us no problems. However, the aim of writing our own overloaded = operator function, and not use the free one, was to find out what exactly happened when we said 'a = b = c;'. That knowlege can be obtained by analysing the output. We notice that C++ first equates the values of c.i and c.j to b.i and b.j, that is, b=c is first executed. C++ does this by making 'b' call the overloaded = operator function with a parameter 'c'. Object 'b' is therefore the current object calling the overloaded operator function. Thus the values of i and j in the overloaded = operator function are those of b.i and b.j, while the values of z.i and z.j are equal to those of c.i and c.j. We now return the current object that is calling the overloaded = operator function, by saying ' return *this; '.
After this step, C++ executes a=b. At this point, the values of both b.i and b.j have become 3. Now 'a' calls the overloaded = operator function with 'b' as a parameter. At the end of the program, the values of a.i and a.j are both equal to 3.
In our overloaded = operator function, instead of saying 'return *this;', we could have just said 'return z;'. After all, if we are equating one object to another, an object can be returned. In that case, our overloaded = operator function would look like
zzz operator = (zzz z)
{
printf("In Operator =%d..j=%d..z.i=%d..z.j=%d\n",i,j,z.i,z.j);
i=z.i;j=z.j;
return z;
}
Our program would still work without problems.
We've probably had enough of the overloaded = operator, so let's get back to doing something different. In the next example, we shall not add two of our own objects, but instead, try to add an object and a number. We have given no default values in our constructor.
opo11.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x,int y)
{
i=x; j=y;
printf("In constructor i=%d...j=%d\n",i,j);
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
a+3;
a.print();
}
Obviously, we can't add an object and a number directly. We shall surely get an illegal structure operation error. So, we simply do what we have, by now, got so used to doing. Insert our overloaded + operator function.
opo12.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x,int y)
{
i=x; j=y;
printf("In constructor i=%d...j=%d\n",i,j);
}
void operator + (zzz z)
{
printf("Operator i=%d...j=%d...z.i=%d...z.j=%d\n",i,j,z.i,z.j);
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
a+3;
a.print();
}
We still get the same error 'illegal structure operation'. We can't insert the same overloaded + operator function, as we had when we were adding two objects. In this case, we are adding a number to an object. In other words, the object is calling the overloaded + operator function with an int as a parameter. The overloaded + operator function has to be modified accordingly, to accept an int.
opo13.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x,int y)
{
i=x; j=y;
printf("In constructor i=%d...j=%d\n",i,j);
}
void operator + (int z)
{
printf("Operator i=%d...j=%d...z.i=%d...z.j=%d\n",i,j,z.i,z.j);
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
a+3;
a.print();
}
OUTPUT:
In constructor i=1...j=1 Operator i=1...j=1...z=3 In print i=1...j=1
Our error now disappears, but we don't know whether our program has actually worked or not, until we assign the output of a+3 to some other object, and then display it.
opo14.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x,int y)
{
i=x; j=y;
printf("In constructor i=%d...j=%d\n",i,j);
}
zzz operator + (int z)
{
printf("Operator i=%d...j=%d...z=%d\n",i,j,z);
zzz d(0,0);
d.i=i+z;
d.j=j+z;
return d;
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
b=a+3;
b.print();
}
OUTPUT:
In constructor i=1...j=1 In constructor i=2...j=2 Operator i=1...j=1...z=3 In constructor i=0...j=0 In print i=4...j=4
In the program above, when the line 'b = a + 3; ' is encountered, C++ first looks to the right of the equal to sign, at 'a+3'. It assumes that 'a' is an object that is calling a function '+' with '3' being passed as a parameter to the function. Since we are giving the result to another object 'b', the overloaded + operator function has to return an object that looks like class zzz. For this reason, we create an object 'd' in the overloaded + operator function. This results in the constructor being called. Within the overloaded + operator function, the result of the addition of the integer z with i is given to d.i, while that of z and j is given to d.j. After this, we return the object 'd'. The line, b.print() now results in the values of i and j being displayed as 4.
Well, if we can say 'a+3', we should also be able to say '3+a'. But the only way to find out is to actually try things out. If we try the program without an operator overloaded function, we shall get an error 'illegal structure operation', because we are trying to add an object to an int. So we shall insert our normal void operator overloaded function into the program.
opo15.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x,int y)
{
i=x; j=y;
printf("In constructor i=%d...j=%d\n",i,j);
}
void operator + (zzz z)
{
printf("Operator z.i=%d...z.j=%d\n",z.i,z.j);
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
3+a;
a.print();
}
In spite of us having an operator overloaded function in the program, our program doesn't work. In the case of a+3, C++ treats this statement as a.+(3). This is possible because 'a' is an object of class zzz and we have the code of zzz within our program. But when we say 3+a, it is equivalent to saying '3.+(a)', This means that we are now trying to call a function '+' with a parameter 'a', by 3 which looks like an int. We have a problem, because we don't have the source code of the 'int' class.
When you are in trouble and face hard times, don't you all turn to a friend. And if that person is a true friend, he, assuming both you and your friend are male, will invite you to share his home, until your condition improves. You may eat the same food that the rest of his family eats. You may use his phone and his computer. You get treated as if you were any other family member. Who knows, if he's a great friend, he'll even let you go out with his wife, especially if you have to get into a 'couples only' discotheque. But, under no circumstances will he allow you to take his money, not even if it is just a loan. After all, he's probably wise enough to know that 'Never a lender nor a borrrower be'. Money can be given to family members only.
If we are stuck out here, in our program, trying to say 3+a, C++ allows us to make use of a friend. If we insert a function 'friend void operator + (int p, zzz z){}' into our class, we shall realise that this friend function gets called when we say '3+a;'.
opo16.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x,int y)
{
i=x; j=y;
printf("In constructor i=%d...j=%d\n",i,j);
}
friend void operator + (int n, zzz z)
{
printf("Operator i=%d...j=%d...\n",z.i,z.j);
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
3+a;
}
We now see that the addition of the friend function has resulted in our program showing no errors on compilation. We might, at this point, ask ourselves, what is a friend function ? It's probably better that we discover a few details about friend functions for ourselves. Let us try to display the address of the 'this' pointer in the friend function.
opo17.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x,int y)
{
i=x; j=y;
printf("In constructor i=%d...j=%d\n",i,j);
}
friend void operator + (int n, zzz z)
{
printf("Operator i=%d...j=%d...n=%d\n",z.i,z.j,n);
printf("Addr of This %p\n",this);
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
3+a;
}
To our surprise, we get an error informing us that the 'this' pointer can only be used within a member function of the class. The error message can only mean one thing. A friend function does not belong to a class. But because the function has been called a friend, it gets treated as if it were any other function of the class. It can now do everything that any other function of the class can do. Except for one thing. Since the friend function is not a member of the class, the 'this' pointer is not given to the friend function. Every other function in the class zzz is rewritten by C++ to have the first parameter of the function as 'zzz *this'. The friend function will not have a 'this' pointer.
We shall now assign 3+a to an object so that we can display the result of the addition.
opo18.cpp:
#include<stdio.h>
class zzz
{
public:
int i,j;
zzz(int x,int y)
{
i=x; j=y;
printf("In constructor i=%d...j=%d\n",i,j);
}
friend zzz operator + (int n, zzz z)
{
printf("Operator i=%d...j=%d...\n",z.i,z.j);
zzz d(0,0);
d.i=z.i+n;
d.j=z.j+n;
return d;
}
print()
{
printf("In print i=%d...j=%d\n",i,j);
}
};
main()
{
zzz a(1,1);
zzz b(2,2);
b=3+a;
b.print();
}
OUTPUT:
In constructor i=1...j=1 In constructor i=2...j=2 Operator i=1...j=1...n=3 In constructor i=0...j=0 In print i=4...j=4
C++ first looks at what is to the right of the equal-to sign in the line b=3+a. Here, we see 3+a. This addition is performed by the friend function. Since an object that looks like class zzz has to be returned to 'b', the friend function is rewritten appropriately. We can now confirm that the friend function actually performs the addition of 3+a.
Destructors
Consider the following program. We have a class zzz. The constructor of the class zzz will have the same name as that of the class, itself. In this program, we have a constructor that gets called with a single parameter. We also have a function that looks just like a constructor, but has a '~' in front of it. We have three objects of class zzz in our program.
ds1.cpp:
#include<stdio.h>
class zzz
{
public:
int i;
zzz(int x)
{
i=x;
printf("In constructor %d\n",i);
}
~zzz()
{
printf("Destructor %d\n",i);
}
};
main()
{
zzz a(1);
zzz b(2);
zzz c(3);
printf("BYE\n");
}
OUTPUT:
In constructor 1 In constructor 2 In constructor 3 BYE Destructor 3 Destructor 2 Destructor 1
We notice that the constructor is called, each time the three objects are created. Since we have created the three objects with the parameters 1,2 and 3, respectively, we can see the order in which the constructors are being called. After the three constructors, we see the printf statement within main() displaying BYE. But it is the output after this line that surprises us. We see the output of the function '~zzz(){}' being displayed. We also notice that this function is being called in reverse order of the creation of the object. Such a function that has the same name as that of the class, but with a ~ in front of it's name is called a destructor. The destructor normally gets called in the reverse order of the creation of objects. The behaviour of a destructor can be better explained by the following program.
ds1.cpp:
#include<stdio.h>
class zzz
{
public:
int i;
zzz(int x)
{
i=x;
printf("In constructor %d\n",i);
}
~zzz()
{
printf("Destructor %d\n",i);
}
};
main()
{
{
zzz a(1);
zzz b(2);
zzz c(3);
}
printf("BYE\n");
}
OUTPUT:
In constructor 1 In constructor 2 In constructor 3 Destructor 3 Destructor 2 Destructor 1 BYE
In the second program, we have inserted a pair of braces, before and after creating the objects in main(). In other words, the printf() is outside the braces. We see that the destructors gets called before the printf function in main is executed.
When an object is created, memory is allocated for that object. But at the end of the braces, the object dies. That is, it is no longer in memory. The destructor is responsible for deallocating the memory that the object originally occupied. The memory that the destructor has freed can then be used by any other application by the computer's operating system. The destructor, like the constructor that accepts no parameters, is given free to us by C++. The reason why we have added our own destructor is to see how a destructor actually works.
We also notice something else about destructors. A single destructor that has no parameters, is sufficient to free memory occupied by a number of objects, irrespective of whether the objects have been created with no parameters, a single parameter, or multiple parameters. This is unlike a constructor which will not work if not passed the right number of parameters. We can create an object of class zzz directly, by saying
' zzz a(10); ', or indirectly by first defining a pointer to the class and then initialising it. This is done by the combination of ' zzz *a;' and ' a = new zzz(10); '. The 'new' is the one who is responsible for allocating the memory for the object. Let us see what happens when we define and initialise a pointer to a class. We retained class zzz as it was in the previous programs.
ds3.cpp:
#include<stdio.h>
class zzz
{
public:
int i;
zzz(int x)
{
i=x;
printf("In constructor %d\n",i);
}
~zzz()
{
printf("Destructor %d\n",i);
}
};
main()
{
zzz *a;
a=new zzz(10);
printf("Addr of a=%p\n",a);
printf("BYE\n");
}
OUTPUT:
In constructor 10 Addr of a=120A:0004 BYE
Whether we create an object of a class directly, or first create a pointer to a class and then initialise it, the end result is the same. That is, an object is created with the constructor being called in both cases. But, the way the destructors are treated, differs. If the object is created directly, the destructor is called at the end of the braces, the object is destroyed and the memory occupied by the object is freed. But, if the object is created by initialising a pointer to the class, the object doesn't die at the end of the brace. As we can see in program ds3.cpp, the destructor is not called at all. To call the destructor we specifically have to include the line ' delete a;' in our program. This is shown in the next program.
ds4.cpp:
#include<stdio.h>
class zzz
{
public:
int i;
zzz(int x)
{
i=x;
printf("In constructor %d\n",i);
}
~zzz()
{
printf("Destructor %d\n",i);
}
};
main()
{
zzz *a;
a=new zzz(10);
printf("%p\n",a);
delete a;
printf("%p\n",a);
printf("BYE\n");
}
OUTPUT:
In constructor 10 1212:0004 Destructor 10 1212:0004 BYE
We see that only when we say 'delete a;' the destructor gets called. However, we also notice that the address of 'a' displayed before and after the delete remains the same. This is true because 'a' is still a valid pointer in the program that is placed somewhere in memory. But by saying 'delete a' , we are telling the operating system that the memory occupied by the object 'a' may now be used by someone else.
If we don't have 'delete a;' in our program, the object doesn't die in memory until the program quits out. If we had an additional pair of braces as in the second program, within which the object was created, at the end of this pair of braces, the object hasn't as yet died. When the program quits out of memory, the operating system may allocate the memory used by the object to some other application. This is because the pointer itself is no longer valid at the end of the program.
Consider the following C program. This program is written in BorlandC.
ppp1.c:
main()
{
printf("Hello");
}
Now press the 'Alt' and the 'C' keys on the keyboard, simultaneously. Make sure that 'Compile' in the dropdown box is selected, and press Enter. In other words, all that we are doing, is merely compiling our program. Now we observe that the C compiler hasn't given us any errors. All that we have got, are a series of warnings. Since we have been ignoring all the warnings that our parents have been giving us, from the time we were kids, we aren't about to start heeding any warnings that, of all things, a C compiler give us.
The C compiler hasn't given us any errors, so we can conclude that the C compiler has recognised the function printf(). This obviously means that the function printf() is part and parcel of the C programming language. We now add a 'p' in front of our function name to get pprintf(). Once again, when we compile this program, we get no errors. Thus we say that the compiler has recognised the function pprintf() to be part of the C programming language. We add another 'p' to the function name to get ppprintf().
ppp2.c:
main()
{
pprintf("Hello");
}
We still get no compiler errors. In fact, irrespective of the number of times we write 'p' in front of function printf(), we never get any compiler errors.
This is because as soon as the C compiler sees a function, that is, a name ending with a pair of round brackets, it says ' I Don't Know Functions !'. If the C compiler encountered statements like ' int i;' , or words like 'for', 'while' and so on, the compiler will replace them with machine language code. However, no compiler will ever understand functions. What we just said about the C compiler recognising printf( ) as part and parcel of the C programming language is simply not true.
If our file name is ppp1.c, the compiler will create a file called ppp1.obj. If the compiler is a Microsoft compiler, the OBJ file that is created follows COFF, that is the Common Object File Format. BorlandC compilers, however follow a different file format called OMF. These two formats are different from each other.
Under Windows95, it is recommended that every OBJ file follow COFF. A COFF file has two parts to it. The first part is the part that the C compiler understands. Here, the compiler goes and places the machine language code for things that it understands like int, while, for, and so on. The compiler knows that, after it has finished it's work, the linker will come on the scene. Therefore the compiler leaves a note for the linker that states, while going through file ppp1.c, it came across a function called printf( ). It put an underscore before the name of the function, and placed _print in the second half of the obj file. If any other functions are also found, they will also be placed in the obj file after putting an underscore before the function name.

When the linker wakes up, it will see that the first part of the file ppp1.obj is machine language code. It will take this part and place it, as it is, in another file called the EXE file. In the second part of file ppp1.obj, the linker will see a list of functions that the compiler found when it went through the file ppp1.c.
In the case of the BorlandC compiler, the linker will go through a LIB file called cl.lib. A LIB file is is nothing but a collection of OBJ files. From file cl.lib, the linker will obtain the code for all the functions present in the second part of the OBJ file. Thus the code of function printf() will be added to the EXE file. The same will be done with any other function present in the OBJ file. Now, let us take a case where the compiler places a function like ppprintf() in the OBJ file. The code of this function is not present in cl.lib. The linker will not tell us, in English, that it hasn't found the code of _ppprintf in cl.lib. Instead, it will inform us that there is an undefined symbol _ppprintf in module ppp1.c.
Before we go on the the next program, there is something that we should all know about OBJ files. When we look at any OBJ file, it is not really possible to pin-point the origin of the OBJ file. Was the file create by a C compiler, or a Pascal compiler, or by something else? There is no way that this question can be answered. This is because any OBJ file is programming language neutral.
Did you ever want to know what butterflies do all day? What if we had our own function that would tell us what butterflies did all day? The next program is going to do just that!
Let us write a program in borlandc\bin called xxx.c. This program calls a single function called butterfly().
xxx.c:
main()
{
butterfly( );
}
Now we just compile the above program. We get no compilation errors, and at the end of compilation, we have an OBJ file called xxx.obj. It is useless trying to build this file. If we do so, we shall get a linker error telling us that there is an undefined external symbol _butterfly in the file xxx.c. This is because the code of function butterfly( ) is not present in xxx.c, neither is it present in the library file which the linker looks at, that is cl.lib. But what if there was some means of adding the code of this function to the file cl.lib, so that the linker would see it? To find out how this is done, read on.
We first write another C file called bfly.c. This file contains the code of the function butterfly(), but does not have a main( ).
bfly.c:
butterfly()
{
printf("Butterflies fly from flower to flower");
}
Once again, we only compile this file. We do not get any errors, and file bfly.obj is created. As of now, there is no connection between the two OBJ files xxx.obj and bfly.obj. Merely creating the OBJ file that contains the code of function butterfly() is not sufficient. We have to put it into the file cl.lib. To do this, we change our directory to c:\borlandc\lib. The name of the program that adds OBJ files into library files is called TLIB. To execute this program, we have to give the name of the name of the particular library file, as well as the entire name of the OBJ file we wish to add into the LIB file. In our case, the command is as shown below.
tlib cl.lib + c:\borlandc\bin\bfly.obj
Remember, this command is executed in the subdirectory c:\borlandc\lib. The
' + ' sign indictes that the OBJ file is being added to the LIB file. After this, we change our directory back to c:\borlandc\bin, and build our program. We now realise that the linker gives us no errors. In fact, the program executes without any problems and tells us what butterflies do all day. This is because the linker has found the code of the function butterfly( ) in the file cl.lib.
Thus, we have shown that a lib file is nothing but a collection of OBJ files. We can add our own obj file to a lib file. Having added an OBJ file to the LIB file, we now have to see how we can delete this OBJ file from the LIB file. After all, we don't want to have much use for a function called butterfly( ) lurking around in one of our library files. The command we use for this purpose, is the same TLIB command, with the ' + ' sign being replaced by a ' - ' sign, as shown below.
tlib cl.lib - c:\borlandc\bin\bfly.obj
Sticking with functions and the way that a linker operates, let's take a look at the next program.
ppp3.c:
main()
{
printf();
}
printf()
{
clrscr();
}
In this program, the code of a function called printf( ) is present. This code merely consists of a call to the clrscr( ) function. This function printf( ) is also present in the LIB file that the linker looks at, namely cl.lib. So, from where will the linker call the code of the function printf( )? From within the file itself, or from cl.lib?
When we execute this program, we find that the screen has been cleared, a clear indication that function printf( ) has been called from within the file itself. In other words, the linker will look at a LIB file to find the code of a particular function only if the code of that function is not present in the same file. If the code of the function is present in the same file, the linker will call the function from within the file itself.
More about functions in C. In our next program, we shall write the largest C program that we all understood well.
ppp4.c:
main( )
{
;
}
Ah, that's the largest C program that we can understand for the simple reason that it does absolutely nothing. We note down the size of the EXE file created by compiling and linking this program. The size we obtained, was 7688 bytes, but this size may differ according to the type of compiler used as well as other factors. We now add what is probably the most common function in the C programming language, namely printf( ), to our program.
ppp5.c:
main( )
{
printf("Hi");
}
Once again, we compile and link this program. The size of the .C file increases by a few bytes but the size of the EXE file created has now increased by a few thousand bytes. The size of our EXE file is 10537 bytes. If we subtract this new size from the previous size, we can easily find out the size of the code of the function, printf( ). The answer we obtain from this subtraction is 2849 bytes. Thus we can safely assume that the size of the code of function printf( ) is 2849 bytes. If we add another printf( ) function to our program, the size of the EXE file should also increase by a similar amount.
ppp5.c:
main( )
{
printf("Hi" );
printf("Hi" );
}
To our surprise, we find that the size of the EXE file obtained on compiling and linking this program has not increased by an additional 2849 bytes, but instead, it has increased by just a few bytes. We add one more printf( ) to the program.
ppp5.c:
main( )
{
printf("Hi");
printf("Hi");
printf("Hi");
}
Once again, we notice that the size of the EXE file hasn't increased by a large amount. Thus we conclude that once the code of a function is present in an EXE file, the linker does not bring additional copies of the code of that function into the EXE file, the next time the same function gets called.
Return values
Consider the following program. In this program, we have defined a variable ' i ' to be of datatype int. After this, we have initialised this variable to the return value of the function abc( ), and displayed the value of ' i '.
ret1.c:
main()
{
int i;
i=abc();
printf(" value of i = %d\n");
}
abc()
{
}
If the return value of a function has not been stated, it is assumed to be an int. In this program, the function abc( ) does not return any specific value. So what could be the value of ' i ', which is initialised to the return value of function abc( ) ? We have no definite answer to this question, as it could be any value.
What if we specifically write a statement that will make function abc( ) return a value ? This is done in the next program.
ret2.c:
main()
{
int i;
i=abc();
printf("value of i = %d\n");
}
abc()
{
return 100;
}
When we run this program, function abc( ) specifically returns a value 100. This is because we have included the statement ' return 100 ' in the function abc( ). The output of the above program is as follows: value of i = 100.
In the next program, we shall remove this return statement. Instead, we shall simply have a statement ' _AX = 100; ' in function abc( ). Internally, the heart of our computer is a small device called a microprocessor. This microprocessor has a number of fixed memory locations known as Registers. One of these registers is called the AX register. So when we say _AX, we are saying _AX is a pseudo-variable that represents the AX register. In the above statement, we are not putting 100 in any memory location, but we are placing it into the AX register. We shall now execute the above program, and look at the value of ' i '.
ret3.c:
main()
{
int i;
i=abc();
printf(" value of i = %d\n");
}
abc()
{
_AX=100;
}
To our surprise, we get the still get the same answer as in the previous program ' value of i = 100 '. Maybe we should give _AX the value 200, and then display the value of ' i '. If we do so, we shall see that the value of ' i ' has now become 200. This means that the the program ret3.c has performed the same task as the program ret2.c. In program ret3.c, a value has been returned to main( ) by function abc(), inspite of the fact that there is no return statement in function abc( ).
In reality, it is program ret2.c that does what we have done in program ret3.c. What we are trying to say is that when we have the statement ' return 100; ', the compiler places 100 in the AX register. So when we say ' i = abc( ); ', the return value of function abc( ) is actually picked up from the AX register. Thus if any function has to return a value, this value is placed in the AX register.
Pointers
Considering the fact that we all have reached upto this point, we can safely assume that we all have some knowledge about pointers. Right now, we are going to build on that knowledge of pointers, but we shall, as always, start from scratch.
Take a look at the first program that we have. We have defined a variable i to be of the datatype, long. We have further initialised this variable to a value of 65536+515. We have also defined three pointers in our program. These pointers, p, q and r, have been defined as pointers to a char, an int, and a long, respectively. We have displayed the addresses of the pointers, as well.
ptr1.c:
main()
{
long i;
char *p;
int *q;
long *r;
i=65536+515;
printf("Address of i=%p\n",i);
printf("Addresses of p=%p, q=%p, r=%p\n",&p,&q,&r);
}
OUTPUT:
Address of i=0001:0203 Addresses of p=13FA:0FF8, q=13FA:0FF4, r=13FA:0FF0
As we can see, the three pointers are located at three different places in memory. Since we have defined i to be of type long, i will occupy four memory locations starting from the address that has been displayed in our program. Because we have given the value 65536+515 to i, the values in these memory locations will be 3, 2, 1 and 0, respectively. This is shown in the table below.
If you are not clear as to how we obtained these values, read the initial part of our tutorial on the C programming language. In the next stage of our program, we initialise all three pointers, p, q and r, to the address of i.
ptr2.c:
main()
{
long i;
char *p;
int *q;
long *r;
i=65536+515;
printf("Address of i=%p\n",&i);
printf("Addresses of p=%p, q=%p, r=%p\n",&p,&q,&r);
p=&i;
q=&i;
r=&i;
printf("%p %p %p",p,q,r);
}
OUTPUT:
Address of i=13FE:0FFC Addresses of p=13FE:0FF8, q=13FE:0FF4, r=13FE:0FF0 13FE:0FFC 13FE:0FFC 13FE:0FFC
Now, all three pointers have been initialised to the location where the variable i starts in memory. From the last line of the output in the above program, we see that the values of p, q and r are all the same as the address of i. In the above program, this address is 13FE:0FFC. Because of this, we can easily access any of the four locations occupied by the variable i through these pointers.
Let us display the contents of the three pointers. In other words, we wish to display *p, *q and *r. Let us start with the first pointer p, whose contents we have to display using a printf( ) function. When we speak of *p, obviously, we are saying that p is a pointer, but we first have to ask ourselves, what is the datatype of *p? The only time we have informed the C about the pointer p, is in the line where p had been defined, that is
' char *p;'. We divide this line into two parts, with *p on the right, in one part, while whatever is to the left of *p is said to be in another part. This is shown below.
char || *p ;
The rule is that whatever is to the left of *p, is the datatype of *p. Here, we can see that it is a char. However, if we use %c to display the value of *p, an ASCII character corresponding to the the value of *p will be displayed. We therefore have to make use of the %d, as we wish to see the actual number which *p is equal to.
Similarly, to display the contents of the other two pointers, we shall make use of %d and %ld, respectively.
ptr3.c:
main()
{
long i;
char *p;
int *q;
long *r;
i=65536+515;
printf("Address of i=%p\n",&i);
printf("Addresses of p=%p, q=%p, r=%p\n",&p,&q,&r);
p=&i;
q=&i;
r=&i;
printf("%p %p %p",p,q,r);
printf("*p=%d\n",*p);
printf("*q=%d\n",*q);
printf("*r=%ld\n",*r);
}
OUTPUT:
Address of i=1404:0FFC Addresses of p=1404:0FF8, q=1404:0FF4, r=1404:0FF0 1404:0FFC 1404:0FFC 1404:0FFC 1404:0FFC *p=3 *q=515 *r=66051
Look at the output of the above program. The variable i in this program is located at the address 1404:0FFC. Thus p is also equal to the same value, 1404:0FFC. Since *p is a char or one location only, the function printf( ) will go to this location and display whatever is present at this particular byte in memory. We find the value at this byte to be 3.
For the next line, *q is an int. By saying *q in the function printf(), we are saying go to location 1404:0FFC and display the int that occupies locations 1404:0FFC and 1404:0FFD. This int is found to be 515. Similarly, *r is a long. Therefore, we are telling the function printf( ) to go to location 1404:0FFC and display the long that occupies four locations starting from this point.
In the next program, for our own convenience, we shall reinitialise i to a new value, 65536+4. Now, the four locations occupied by the long in memory will be 4, 0, 1, 0, as shown in the table below.
We have also defined three more variables, x, y and z. These have been defined as ' char **x; ' , ' int **y; ' and ' long **z; '. Thus, we can see that all three variables are pointers of some sort. More about that later. We first display the addresses of these three pointers. The addresses displayed can be any value. After this, we initialise all the three pointers to the address where i starts in memory. After this, if we display x, y and z, we shall see that their value is the same, that is, the address of i.
ptr4.c:
main()
{
long i; char *p; int *q; long *r;
char **x;
int **y;
long **z;
i=65536+515;
printf("Address of i=%p\n",&i);
printf("Addresses of p=%p, q=%p, r=%p\n",&p,&q,&r);
p=&i; q=&i; r=&i;
printf("%p %p %p %p \n",&i,p,q,r);
printf("*p=%d\n",*p);
printf("*q=%d\n",*q);
printf("*r=%ld\n",*r);
i=65536+4;
printf("Before initialising %p %p %p\n",&x,&y,&z);
x=&i;
y=&i;
z=&i;
printf("After initialising %p %p %p\n",x,y,z);
}
OUTPUT:
Address of i=140B:0FFC Addresses of p=140B:0FF8, q=140B:0FF4, r=140B:0FF0 140B:0FFC 140B:0FFC 140B:0FFC 140B:0FFC *p=3 *q=515 *r=66051 Before initialising 140B:0FEC 140B:0FE8 140B:0FE4 After initialising 140B:0FFC 140B:0FFC 140B:0FFC
We now realise that the values of six variables p, q, r, x, y and z are all equal to the address of i, which in this program is 140B:0FFC. We now have to display the values of *x, *y and *z. Once again we ask ourselves what the datatype of *x is. To find the answer to this query, we follow the same procedure as before. We take a look at the line where x was initialised. We divide the definition into two parts. We have *x in one part, while the other part contains everything to the left of *x in the definition. This is as shown below.
char * || *x;
Thus we can see that the datatype of *x is a pointer to a char. To display this pointer, we will have to use %p in the function printf( ). Similarly, to display *y and *z also, we shall have to use %p, as shown in the next program.
ptr5.c:
main()
{
long i; char *p; int *q; long *r;
char **x;
int **y;
long **z;
i=65536+515;
printf("Address of i=%p\n",&i);
printf("Addresses of p=%p, q=%p, r=%p\n",&p,&q,&r);
p=&i; q=&i; r=&i;
printf("%p %p %p %p \n",&i,p,q,r);
printf("*p=%d\n",*p);
printf("*q=%d\n",*q);
printf("*r=%ld\n",*r);
i=65536+4;
printf("Before initialising %p %p %p\n",&x,&y,&z);
x=&i;
y=&i;
z=&i;
printf("After initialising %p %p %p\n",x,y,z);
printf("*x = %p\n",*x);
printf("*y = %p\n",*y);
printf("*z = %p\n",*z);
}
OUTPUT:
Address of i=1413:0FFC Addresses of p=1413:0FF8, q=1413:0FF4, r=1413:0FF0 1413:0FFC 1413:0FFC 1413:0FFC 1413:0FFC *p=3 *q=515 *r=66051 Before initialising 1413:0FEC 1413:0FE8 1413:0FE4 After initialising 1413:0FFC 1413:0FFC 1413:0FFC *x = 0001:0004 *y = 0001:0004 *z = 0001:0004
When we display the values of *x, *y, *z, we realise that they all show the same value, 0001:0004. But what is the significance of this value? All this while, we have being saying that a pointer occupies four bytes. While this statement is true, a pointer is simply not stored as a long. Instead, a pointer is stored as two ints.
If we look closely at table 2, we shall see that we can divide the long number into two ints. Look at the int that is stored in the first two locations. We see that this value is 4 and can be written as 0004. The int stored in the next two locations is 1, which we can write as 0001. If we first write the second number, followed by the first number, both separated by a colon, we shall get 0001:0004. This is exactly the value that *x displays for us. Since *x is a pointer, we have shown that a pointer is nothing but two ints. The int stored in the first two bytes, in the table2 shown above, is called the offset, while the int stored in the next two bytes is called the segment. However, the int in the last two bytes is normally written first. That is, the segment is written before the offset.
The reason why a pointer is stored as two ints has a lot to do with the history of microprocessors. To access any memory location, we have to make use of registers. On the 8086 microprocessor, the registers were only 16 bits in length. Therefore, numbers in the range of 0 to 65535 could fit in a single register. Using a single register, we access only 64 KiloBytes of memory. To enable the microprocessor to access a much larger amount of memory, it was decided to use a combination of two registers. One register is multiplied by 16 while the other register is multiplied by 1, and the result of both the multiplications is added to get the actual address. Using this method, we can access a massive amount of memory that would otherwise not be possible with a single register. Taking the case of our program, to get the actual address, we perform the following calculation:- 1*16 + 4*1 = 20.
We should keep one thing in mind. The same address location can be accessed by having different combinations of the two registers that store the pointer, ie the segment and the offset. For example, to access the address location 50, we may use any of the combinations shown in the table below.
Segment | Offset 0 | 50 1 | 34 2 | 18 3 | 2
Having talked so much about the history of microprocessors, pointers are no longer stored in the segment:offset combination. Instead, from the 386 microprocessor onwards, when pointers are stored, they make full use of 32 bit registers and are stored as a single number, avoiding the need of the segment:offset combination.
Now that we have learnt so much about pointers, we are ready to go even further into building our knowledge about the fundamentals of the C programming language. The next section of this tutorial will tell us what exactly happens when files are handled in C. Consider the following program. Here, we assume that we already have a file called zz.c, which we are trying to open in the read mode.
fopen1.c:
main()
{
char *p;
int i;
p=fopen("zz.c","r");
while((i=fgetc(p))!=-1)
printf("%c",i);
}
We compile and link this program without getting any errors. However, when we execute this program, we realise that there is no output. The file zz.c does not get displayed.
In the next program, we make a small modification to the previous program. We add the line ' #include<stdio.h> '.
fopen2.c:
#include<stdio.h>
main()
{
char *p;
int i;
p=fopen("zz.c","r");
while((i=fgetc(p))!=-1)
printf("%c",i);
}
We now realise that the file, zz.c is displayed when we execute the above program. A point to be noted is that the file zz.c gets displayed inspite of the fact that nowhere in this program have we defined a variable that is a pointer to FILE.
In the next program, p is defined as a pointer to an int.
fopen3.c:
#include<stdio.h>
main()
{
int *p;
int i;
p=fopen("zz.c","r");
while((i=fgetc(p))!=-1)
printf("%c",i);
}
Once again, the file zz.c gets displayed without any problems. We may even define p to be a pointer to a long as ' long *p; ', or a pointer to a void as ' void *p; '. In fact, we can define p as a pointer to a pointer, in the above program. It does not matter if we define p as ' void ****p;' or ' int **p; '. When we execute program fopen3.c, the file zz.c will get displayed. By now, we all must have realised that the mere inclusion of the header file stdio.h in the program, is actually responsible for the file zz.c getting displayed. Thus, something in this header file makes sure that the file gets displayed.
Our aim should be to replicate the effect that the inclusion of the header file has on our program. In the next program, we remove the line ' #include<stdio.h> ' from our program. All that we put, is a function prototype of fopen( ), in it's place.
fopen4.c:
int *fopen();
main()
{
int *p;
int i;
p=fopen("zz.c","r");
while((i=fgetc(p))!=-1)
printf("%c",i);
}
Inspite of the fact that there is no header file in the above program, we see that the file zz.c gets displayed. We now make some modifications to this prototype by saying that the return value of fopen( ) will be a pointer to a void.
fopen5.c:
void *fopen();
main()
{
int *p;
int i;
p=fopen("zz.c","r");
while((i=fgetc(p))!=-1)
printf("%c",i);
}
The way this program is shaping up does upset us a bit. After all, the file zz.c gets displayed once again. Change this prototype to ' char *fopen( ); ' or ' int ***fopen( ); ' or even ' long **fopen( ); '. The file zz.c always gets displayed. But remove the prototype totally, and the file does not get displayed.
Time to explain this mystery. When C looks at fopen( ), it knows that fopen( ) is a function. By default, a function returns an int, so C will assume that fopen( ) returns an int. However, the variable p, which accepts the return value of the function fopen( ), has to be a pointer. In other words, a segment and an offset has to be filled up by the return value of the function fopen( ). If the prototype is not present, function fopen( ) will return an int and the equal-to sign will fill up only the offset of the variable p. The segment is not filled up.
But if C is told that fopen( ) returns a pointer, the return value of the function fopen( ) creates a structure that looks like FILE. Now, the segment will be stored in the DX register and the offset will be stored in the AX register.
The function fgetc( ) accepts a parameter, p. Unless a pointer is on the stack, this function will not work as we expect it to work.
One thing that we have to emphasize is the fact that the program works only because of one simple reason. All we have done with the pointer p, is to pass it to function fgetc( ). Nowhere in the program, have we made statements like p++, p--,
p->, **p and so on. Only because we didn't do any of the following, it doesn't matter what we define p as a pointer to.
Take a look at the program shown below.
psp1.c:
#include<dos.h>
main()
{
printf("%u\n",_psp);
}
All that we are trying to do, is display a variable called _psp. Notice that we haven't created a variable by this name, anywhere in the program. Everytime we try to display a variable that hasn't been defined in the program, we get a compilation error.
In this program, however, we realise that the compilation process takes place without any errors, and some value gets displayed on execution. This means that the variable _psp is valid. We shall be explaining this variable _psp in a short while.
We have already said that all pointers are made up of a segment and an offset. Now let us look at how EXE files communicate with DOS. Look at the diagram 1 shown below. Assuming that memory starts from the bottom, let's also assume that DOS occupies the first section. Also assume that our EXE file has been allocated memory at a location as shown in the figure, that is, it is loaded at that location.
As we all know, a pointer occupies four bytes in memory. But to get these four bytes, the segment is multiplied by 16 and added to the offset. The number thus obtained, gives us the required address.
This means that everytime we want to access a pointer, we have to read and write four memory locations. All this slows down the operation of the machine. Suppose all our pointers begun at a location in memory that was divisible by 16, then the offset would always be zero. This is precisely what DOS does. Whenever DOS has to allocate memory for anything, the memory is always allocated in multiples of 16. The memory allocated always begins at a number divisible by 16 and ends at a number divisible by 16. Thus, as far as DOS is concerned, all pointers are only read as two bytes, as the offset is always zero.
Lets assume that DOS loads our program at a particular location in memory. This has to be a memory location divisible by 16. If the EXE file has to obtain any information that it needs from DOS, there has to be a way by which DOS can communicate with the EXE file. This is why DOS allocates an additional area of memory that is 256 bytes large. This, once again, is a number divisible by 16. Assume that this DOS has allocated this memory at 96. As we can see, 96 is a number divisible by 16. This number is equivalent to segment 6, and the pointer can be written as 0006:0000. To get the actual address, we don't even bother about the offset, as it is not important. We simply multiply 6 by 16 to get 96.

These 256 bytes that DOS has allocated for each EXE file are called the psp or the program segment prefix. These 256 bytes are actually divided into two halves, each made up of 128 bytes. The first half is from 0 to 127, while the second half starts 128 bytes from the start of the psp. Suppose our exe file is called psp2.exe, and it is to be executed along with command line arguments 'abc' and 'pq'. When we execute our EXE file by writing
' psp2 abc pq ' at the DOS prompt, we find that at the location 128 bytes from the start of the psp, the number 7 has been placed. If we look at what we have written exactly after the name of our EXE file, we shall see 7 characters, including the spaces. This is the number that has been placed at byte 128 of the psp. Following this number is the actual data, or arguments, that we placed after the name of the file while executing it.
What actually happens is that DOS starts the execution of the EXE file. Every EXE file has a header. Two bytes of this header inform DOS where the CS:IP is stored. This CS:IP is an address where the first executable instruction is located. The first executable instruction is called the startup code. Every compiler has it's own startup code, which is a program that is normally written in assembler and compiled. In the case of BorlandC, this assembler program is called c01.asm, which, after compilation, becomes c01.obj. If this particular file was not present in Borlandc\lib, no program in Borlandc would work. It is the job of the linker to get the startup code and insert it into every program. If the required obj file that contained the startup code is not present, our program would get a linker error. Thus the startup code always gets executed before anything else in the program. The first thing that is done by this startup code, is the creation of a variable called _psp. The startup code is responsible for counting the number of arguments following the file name. It counts the number of characters, creates an array of pointers to chars, and puts these characters on the stack.
There is a line in the startup code that says ' call _main '. This is the reason why main( ) is always the first function to get called in a C program under DOS. We should realise that DOS itself is not going to create an array of pointers to chars for all our programs. This is because other types of applications, for example, Clipper, may not understand what these pointers to chars stand for. This is why the startup code has to create this array for us. Knowing how the bytes of the psp are organised, we can write a program to display the number of characters that have been typed in, as arguments, after the name of the file, while executing the program. We can also display all these characters in our program.
psp2.c:
#include<dos.h>
main()
{
char *p;
int i,j;
p=MK_FP(_psp,128);
i=*p;
printf("Number of characters: %d\n",*p);
p++;
for(j=1;j<=i;j++)
{
printf("%c",*p);
p++;
}
}
OUTPUT:
Number of characters: 7 abc pq
The function MK_FP( ) is a macro that will return a pointer to the 128th bit of the psp. It multiplies the first parameter by 16, and adds the second parameter to this value, to obtain the address of the 128th bit of the psp. The contents of this bit will give us the number of arguments that have been given after the name of our program, while executing the program. Assume that we had written ' psp2 abc pq ' while executing our program, this number would be 7. This number is stored in a variable i. We then use a for loop to display the array of arguments starting from the 129th bit. This loop repeatedly executes for a certain number of times, equal to the number stored in the variable, i.
Of course, if we were running our programs under Windows, the startup code would have to be different. Here, instead of calling main( ), we have to call WinMain( ). In case of programs under Windows, four members are put on the stack. Thus, the startup code has to be different.
As programmers, we have to make optimum use of the facilities that are given to us by the operating system. It will be to our advantage that we learn as many features of the operating system we are working on. The more the operating system offers us, the less is the work we have to do achieve the same end results. DOS was written in assembler, so whenever we have to use features of DOS, it is always preferrable to make use of assembler code. In case of Windows, since it was written in C/C++, we preferrably use C/C++ when we wish to make use of the features of Windows.
Earlier, in C under DOS, we had made use of a few interrupts that were hardware interrupts, ie hardcoded into our ROMBIOS. These were the interrupts 8 and 9. These interrupts represent a preset timer and the keyboard interrupt respectively. However, these interrupts perform only one task, after which, their execution is terminated. However, there are other interrupts like interrupt10H, which can perform a number of tasks. There is a function called geninterrupt( ) that, when given an interrupt number, will generate that interrupt for us. All these interrupts looks into the AH register. Based on what the AH register contains, the other registers will further tell the interrupt what exactly has to be done.
int1.c:
#include<dos.h>
main()
{
_AH=0;
_AL=0;
geninterrupt(0x10);
}
In the next couple of programs, we shall be calling interupt10H, using geninterrupt( ). Interrupt mainly deals with vorious aspects of the screen. In this program, we have placed 0 inside the AH register, which indicates that the target of this interrupt is going to be the mode in which characters are displayed on our screen. When we place 0 in AH, we can change the size of the characters on screen. The value in the AL register will inform the interrupt as to what mode the screen should be displayed in. We have placed 0 in the AL register. When we run our program, we see that the size of the characters we now type at the DOS prompt on our screen has changed. They now appear much larger than before. Also, if we type the command ' bc ', we shall see that BorlandC no longer appears in colour. Instead, it now has a dull Black and White interface. To get our screen back to normal, type the following command at the DOS prompt : mode co80. The size of the characters return to normal, and the BorlandC interface gets its original colour back. We may try changing the value in the AL register to 1, 2, 3... to determine the other modes that the interrupt can force the screen to change to.
Look at our next program. It generally follows the same principle of first looking at the AH register to decide what the target of the interrupt is going to be. Further, int10H will do something on the device selected, based on the values of the other registers. The number 1 in the AH register denotes that the interrupt is going to perform some activity on the cursor on our screen.
int2.c:
#include<dos.h>
main()
{
_AH=1;
_CH=2;
_CL=4;
geninterrupt(0x10);
}
When we run this program, we are disappointed to see that nothing has really changed. So did the interrupt perform it's task or not? Before we answer that question, let us change the values in the CH and the CL registers in the next program.
int3.c:
#include<dos.h>
main()
{
_AH=1;
_CH=7;
_CL=1;
geninterrupt(0x10);
}
Now, when we run our program, we see a massive cursor spanning the entire height of a single line. We can now confirm that program int2.c did indeed work. But since it resulted in a cursor size that was similar to that of a normal cursor, it was difficult to notice the difference. Time to play a couple of tricks with our cursor. Have you ever wanted to see a cursor that was at the top of the line, rather than at the bottom? Change the values in registers CH and CL to 1 and 2 respectively. Experiment a little more with the values in CH and CL.
By the time you finish reading this tutorial, you'll probably have a good idea about how computers used to function in the days gone by, the changes that came along the way, and how to exploit these changes to the maximum. Hey, don't we all want to learn new technology? Sure, but it definitely pays to get our basics strong, before taking the next step. So, here we go, into another round of history. In the good old days, when computers first came on the scene, all that we had, to view the output of our programs, were monochrome monitors. Yes, you're right , those ordinary black and white screens. Each character took up two bytes of screen memory, and a total of two thousand characters could be displayed. Thus, only 4K of screen memory was required. But with the advent of colour monitors, colour cards were introduced to cope up with the additional demands. These cards could handle a total of 16 K of screen memory. Thus, we now have 16 K at our disposal. But a single screen still needs only 4K, which meant that we can now have four screens, each of 4K. Each screen is called a page. Only one page will be visible at any given time, the rest will be hidden. But it is possible to move from one page to another, as can be seen in the next two programs. Both these programs should first be written and compiled, before we run either of them.
page0.c:
#include<dos.h>
main( )
{
_AH=5;
_AL=0;
geninterrupt(0x10);
}
page1.c:
#include<dos.h>
main( )
{
_AH=5;
_AL=1;
geninterrupt(0x10);
}
In these programs, when interrupt10 sees the value 5 in the AH register, it knows that the value in the AL register will contain the number of the page to be displayed. As we said earlier, with colour cards, we can have four pages. Assume we are at the DOS prompt, at borlandc\bin. Here, type the command ' page1 '. We shall realise that the DOS prompt is at the top of a blank screen. Run the command 'dir n* '.
We get some output on the screen. Now, run the first program by saying ' page0 '. To our surprise, we shall see that the screen where we had written ' dir n* ' is no longer present. Instead, we see a screen that shows the last command executed as ' page1 '. If we once again give the command ' page 1', we reach a screen where we had said ' dir n* '. We therefore realise that we have been moving between two pages or two screens. Experiment with page numbers 2 and 3, in the AL register.
Using this same principle, we shall write yet another program to create a screen saver. The principle of this screen saver is quite simple. We create two pointers to chars, s and t. The first is a pointer to page 0, while the second is a pointer to page 1. In other words, the first pointer s is initialised to 0xB8000000, while the second pointer t is initialised to 0xb8000000+4096.. Every character on the first page is written to the second page, using these two pointers. A delay is introduced, during which, we display numbers upto 1000. After the delay, the second page is copied back to the first page.
scrsave.c:
#include<dos.h>
main()
{
int i;
char *s=0xb8000000;
char *t=0xb8000000+4096;
for(i=0;i<=4000;i++)
*(t+i)=*(s+i);
for(i=0;i<=1000;i++)
printf("%d\n",i);
for(i=0;i<=4000;i++)
*(s+i)=*(t+i);
}
The next set of programs looks at structures and unions, and tells you about the differences between the two.
struct1.c:
main()
{
struct
{
char i;
int j;
long k, l;
}zz;
printf("Addr of zz %p\n",&zz);
printf("Addr of zz.i %p\n",&zz.i);
printf("Addr of zz.j %p\n",&zz.j);
printf("Addr of zz.k %p\n",&zz.k);
printf("Addr of zz.l %p\n",&zz.l);
zz.k=65536+515;
printf("zz.k = %ld\n",zz.k);
printf("zz.i=%d....zz.j=%d....zz.l=%ld\n",zz.i,zz.j,zz.l);
printf("size of(zz) = %d\n",sizeof(zz));
}
OUTPUT:
Addr of zz 1408:0FF4 Addr of zz.i 1408:0FF4 Addr of zz.j 1408:0FF5 Addr of zz.k 1408:0FF7 Addr of zz.l 1408:0FFB zz.k = 66051 zz.i=4....zz.j=-508....zz.l=1343361029 sizeof(zz) = 11
Consider the following C program. We have a structure that is made up of four variables, a char, an int and two longs. We have displayed the addresses of all four variables. The members of the structure are arranged as shown below. Only the first variable has the same address as that of the structure.
We have initialised only one of these variables, namely k, to 65536+515. Obviously, when we display the other variables, we cannot predict what values will get displayed as we have not initialised them. The size of the structure is 11.
The next program is almost similar, except for the fact that instead of having a structure called zz, we now have a union called zz. This union is made up of exactly the same members as that of the structure zz. Thus, we are saying that when you consider syntax of both a structure and a union, they are exactly the same. The rest of the program is also the same.
union1.c:
main()
{
union
{
char i;
int j;
long k, l;
}zz;
printf("Addr of zz %p\n",&zz);
printf("Addr of zz.i %p\n",&zz.i);
printf("Addr of zz.j %p\n",&zz.j);
printf("Addr of zz.k %p\n",&zz.k);
printf("Addr of zz.l %p\n",&zz.l);
zz.k=65536+515;
printf("zz.k = %ld\n",zz.k);
printf("zz.i=%d....zz.j=%d....zz.l=%ld\n",zz.i,zz.j,zz.l);
printf("size of(zz) = %d\n",sizeof(zz));
}
OUTPUT:
Addr of zz 1408:0FFC Addr of zz.i 1408:0FFC Addr of zz.j 1408:0FFC Addr of zz.k 1408:0FFC Addr of zz.l 1408:0FFC zz.k = 66051 zz.i=3....zz.j=515....zz.l=66051 size of(zz) 4
We now realise that all the variables that are members of the union begin at the same address. Also, the size of the union is 4, as compared to 11 for the equivalent structure. This means that the size of the union doesn't depend on the number of members within the union, and is not the sum of the size of each member, as in the case of a structure. A union simply occupies an area of memory that it's largest member occupies. In the case of our union, the largest member is a long, so the union occupies four bytes, as shown in the figure below. This is a major difference between stuctures and unions. The consequences of this difference is also quite drastic. By changing merely a single byte, we may end up changing the values of all four variables that are members of the union.
For example, in our program union1.c, we have merely initialised a single variable, namely k, as we did in the program struct1.c. In that program, initialising a single variable had no effect on the other variables, as all the variables occupied different memory locations. In this program, however, the other variables will take the values based on the value of k. As k was initialised to 65536+515, the four memory locations occupied by the union will have the values 3, 2, 1 and 0. Since i is a char, it occupies the first location in the union, and is equal to 3. The int j occupies the first two memory locations, and therefore will be equal to 515. Both the longs, k and l, occupy all four bytes, therefore both are equal to 66051.
Try changing the value of the char, and see what effect it has on the other variables.
Time to move on to slightly more complicated unions. We first write a header file called zzz.h as shown below. This header file has a union called REGS. This union further has two members which are both structures. The size of this union will be the size of the largest structure. But, we observe that the size of both the structures is the same, ie. both structures are four bytes in length. This is because one structure is made up of four chars, while the other is made up of two ints.
zzz.h:
struct hh
{
char al;
char ah;
char bl;
char bh;
};
struct xx
{
int ax;
int bx;
};
union REGS
{
struct xx x;
struct hh h;
}
The header file shown above, is included into our next program, with the double quotes indicating that the header file is in the current directory.
uregs.c:
#include"zzz.h"
main()
{
union REGS a;
printf("size %d\n",sizeof(a));
printf("Addr of a %p\n",&a);
printf("Addr of a.x %p\n",&a.x);
printf("Addr of a.h %p\n",&a.h);
printf("Addr of a.x.ax=%p...a.x.bx=%p\n",&a.x.ax,&a.x.bx);
printf("Addr of a.h.al=%p...a.h.ah=%p...a.h.bl=%p...a.h.bh=%p\n",
&a.h.al,a.h.ah,a.h.bl,a.h.bh);
a.x.ax=300;
printf("a.h.al=%d...a.h.bl=%d\n",a.h.al, a.h.bl);
a.h.bl=10;
a.h.bh=1;
printf("a.x.bx=%d\n",a.x.bx);
}
OUTPUT:
size 4 Addr of a 140A:0FFC Addr of a.x 140A:0FFC Addr of a.h 140A:0FFC Addr of a.x.ax=140A:0FFC...a.x.bx=140A:0FFE Addr of a.h.al=140A:0FFC...a.h.ah=140A:0FFD...a.h.bl=140A:0FFE ...a.h.bh=140A:0FFF a.h.al=44...a.h.bl=112 a.x.bx=266
The above program and the output it generates, at first glance, appears to be quite complicated. When we look at the diagram shown below, things begin to look a lot clearer. We have first displayed the addresses of the union a, as well as those of it's members, the structures x and h. We see that all three addresses are the same. The members of the structure x are two ints, ax and bx. Since they are actually members of a structure x within a union a, we can access them using a.x.ax and a.x.bx. We display the addresses of ax and bx, as well. Similarly, we also display the addresses of all the members of the structure h. We shall see that arrangement of variables is as shown in the figure.

We now assign a value of 300 to a.x.ax. The variable ax is an int, therefore this value will be stored as 44 and 1. In the next line, we have displayed the values of al and bl. Since al occupies the same location as the first byte of ax, it's value will be displayed as 44. However, we haven't initialised anything beyond the first two memory locations occupied by the union. Therefore, the value of bl may be displayed as anything. Similarly, we may initialise bl to 1 and bh to 10. These two memory locations are also occupied by the int bx. Therefore, bx will be displayed as 256*1+10=266.
By now, a thought might have struck you. Doesn't the microprocessor have a sixteen bit AX register which is made up of two parts of eight bits each, called AL and AH ? And when we change the value in AX, don't the values in AL and AH automatically change? Isn't the reverse also true, that is, when we change values in AL and AH, doesn't the value in AX also change?
There is actually a union called REGS defined in the header file, dos.h. This union is similar to the union we have defined in our header file 'zzz.h', though it actually has a few more members. We are going to include the header file, dos.h, in our next program to enable us to accesss the members of this union.
intA.c:
#include<dos.h>
main()
{
union REGS a,b;
a.h.ah=9;
a.h.al=65;
a.h.bl=25;
a.h.bh=0;
a.x.cx=50;
int86(0x10,&a,&b);
}
Before we explain this program, we shall first run it. A line of fifty A's gets displayed, all in blue. If we count the number of alphabets displayed, we see that there are exactly fifty. This is the number that is present in cx, which is a member of the structure x, itself a member of the union a. We also see that 65 has been placed in al, which is why all the letters displayed are capital A's. The attribute of each character displayed on screen, is placed in bl. We have chosen 25, which represents the colour blue. Remember all that talk about page numbers of our monitor? The 0 in bh refers to the page we are writing to. Placing 9 in ah refers to the fact that we want to write to screen. But, until now, we have merely initialised the values present in a union. All these values have to go into the appropriate registers, and an interrupt has to be called, before we see anything on our screen. To do all this, we call the function, int86( ). This function looks at the second parameter, in this case &a. We are passing the function the address of a union a, that looks like REGS. This union has two structures as members, which in turn have their own members. Starting from this address, the values present in all the members of the union will be loaded into predefined registers. For example, whatever is in a.h.al, a.h.ah, a.h.bl, a.h.bh, a.x.cx, etc will be loaded into the registers AL, AH, BL, BH, CX and so on. After this, function int86( ) looks at the first parameter and calls interrupt 10H. This interrupt will perform the assigned task as specified by the values in certain registers. In this case, it will write the alphabet A to screen on page0 in blue, fifty times. The values that are present in all the registers after the interrupt has been executed may be different from the original values. These new register values are returned to the union b, which also looks like REGS and is specified as the third parameter of the function int86( ).
Actually, the same effect can be achieved by using the function geninterrupt( ), that we had used earlier.
intAA.c:
#include<dos.h>
main()
{
_AH=9;
_AL=65;
_BL=25;
_BH=0;
_CX=50;
geninterrupt(0x10);
}
The next program will replicate the manner in which a directory is created internally by DOS. In fact, we shall be creating a really cool directory. We define p as a pointer to a char. After this, p is initialised to the address of a string, cool. This is the name of the directory we wish to create. A pointer has a segment and an offset. To create a directory, the offset of this pointer has to be stored in the DX register, while the segment has to be stored in the DS register. To divide a pointer into it's segment and it's offset, we make use of two functions, FP_OFF( ) and FP_SEG( ). The pointer has to be pased as parameter to both these functions. These functions, FP_OFF( ) and FP_SEG( ), return the offset and the segment of the pointer p, respectively. Placing 0x39 in a.h.ah tells interrupt 21H that a directory has to be created.
intB.c:
#include<dos.h>
main()
{
union REGS a,b;
char *p;
a.h.ah=0x39;
p="cool";
a.x.dx=FP_OFF(p);
a.x.ds=FP_SEG(p);
int86(0x21,&a,&b);
}
When we execute this program, we get an error saying ' undefined symbol ds '. We change our directory to c:\borlandc\include and type ' edit dos.h '. Here, we see that the union called REGS has two structures as members. None of these structures have a member called ' ds ', which is why we get an error. While still in dos.h, we can search for
' ds ', matching whole word as well as case. We find ' ds ' present in a structure tag called SREGS. Coming back to our program, we define a structure s of type SREGS. We now initialise s.ds to the return value of FP_SEG( ).
Instead of the function int86( ), we use a slightly different function, int86x( ). We are forced to use this function because there was no way that function int86( ) could handle members of the structure s that look like SREGS. The function int86x( ), in addition to doing all that int86( ) does, can also load s.ds into the segment register DS.
intC.c:
#include<dos.h>
main( )
{
union REGS a,b;
char *p;
struct SREGS s;
a.h.ah=0x39;
p="cool";
a.x.dx=FP_OFF(p);
s.ds=FP_SEG(p);
int86x(0x21, &a, &b, &s);
}
Now when we compile this program, we get no errors. Before running this program, check if there is any directory called ' cool '. If one is present, delete it. Now, run this program and once again, check for a directory called ' cool '. We shall see a freshly created directory of this name.
This is, in fact, exactly the way DOS creates a directory. A pointer to a char is created and initialised to the string that contains the name of the required directory. The offset of this pointer is stored in the DX register, while the segment is stored in the DS register. After this, interrupt 21H is called, which is actually responsible for the creation of the directory.
The program to delete a file is very similar to the way a directory is created. We once again have to make use of interrupt 21H, and place the segment and the offset of the pointer to the file in registers DS and DX. The only difference is that we now have to place 41H in the AX register.
intD.c:
#include<dos.h>
main( )
{
union REGS a,b;
char *p;
struct SREGS s;
a.h.ah=0x41;
p="z.c";
a.x.dx=FP_OFF(p);
s.ds=FP_SEG(p);
int86x(0x21, &a, &b, &s);
}
Using the same interrupt 21H, we can do a couple of other things like renaming a file. This will be shown in the next program. Let's assume that we have a file called z.c, and want to rename it to interrupt.c. To accomplish this, we have to create two pointers to chars which we have called ' name1' and ' name2 '. These pointers are initialised to " z.c " and " interrupt.c ", respectively. The offset of name1 has to be stored in the register DX, while the segment has to be stored in register DS. Similarly, the offset and segment of name2 have to be stored in the registers DI and ES, respectively. While dx and di are members of the union REGS in dos.h, ds and es are members of the structure SREGS.
intE.c:
#include<dos.h>
main()
{
union REGS a,b;
char *name1;
char *name2;
struct SREGS s;
a.h.ah=0x56;
name1="z.c";
name2="interrupt.c";
a.x.dx=FP_OFF(name1);
s.ds=FP_SEG(name1);
a.x.di=FP_OFF(name2);
s.es=FP_SEG(name2);
int86x(0x21, &a, &b, &s);
}
When we run this program, we shall see a new file called ' interrupt.c ' in our current directory. This file is merely the file ' z.c ' that has been renamed as ' interrupt.c '.
Calling Conventions
We first write the smallest C Windows program using Microsoft VC++ 5.0, which is as shown below.
call1.c:
int _stdcall WinMain( void *i, void *j, char *k, int l )
{
}
We make a note of the size of the exe file obtained after compiling and linking the above program. This is done, in DOS, by going to the directory c:\call1\debug and saying dir.
As compared to previous C Windows programs, there are a few changes. Until now, we had been telling you that the first two parameters of the function WinMain() are of type HINSTANCE. We also said that the macro HINSTANCE is an ' unsigned int '. The first noticeable change in this program, is that we have replaced HINSTANCE by ' void * ' for both the parameters, i and j.
In fact, under Windows95, all handles are ' void * '. Let us revise all that we have learnt about handles. First of all, a handle is a number that makes no sense to us. However, this number makes sense to someone else, namely Windows95. It is not for us to interfere with this number.
The reason why handles are made ' void * ' is because people who call themselves programmers, the world over never follow basic rules. Even if it has been clearly mentioned that we should never touch a handle's value, these so called programmers are capable of trying to increment or decrement a handle, by saying ' i++ ' or ' i-- '. They are even capable of attempting things like ' i. ' and ' i-> '. However if ' i ' is defined to be of type ' void * ', and these self-proclaimed geniuses try any of the above mentioned things that attempt to change the value of ' i ', they will get an error. If we use some common sense, the reason for the error becomes pretty obvious. Let's assume that we have a pointer to a char, as in the statement ' char *i; ', and we increment it by saying ' i++ '. This pointer has been defined to be of type char, so when we increment ' i ', it gets incremented to point to the next memory location. Similarly, when we increment a pointer to an int, it now points to an address location that is two more than the previous location. In other words, a pointer to an int increments, each time, by the number of bytes occupied by an int, that is, two memory locations. However, if we try to increment a pointer to void, how much will it increment by ? A void represents nothing, so is it possible to increment the pointer by void? We have no answer to this question, and neither does the C compiler. We therefore get an error telling us that the size of void is unknown.
Let's go one step further in our program, and include a MessageBox in our program.
call2.c:
int _stdcall WinMain( void *i, void *j, char *k, int l )
{
MessageBox(0,"Hi","Bye",0);
}
If we now execute this program, we get a linker error saying ' unresolved external symbol _MessageBox '.
All that wehave to do to remove this error, is to include the header file, windows.h, as shown in the next program.
call3.c:
#include<windows.h>
int _stdcall WinMain( void *i, void *j, char *k, int l )
{
MessageBox(0,"Hi","Bye",0);
}
If we execute our program, we shall see a MessageBox which probably tells us a lot about the relationship we share with our friends, these days - Hi and Bye !
Before we talk about why the error now vanishes, let's remind ourselves about the basics of the compilation process. We should have one thing very clear in our mind. Whenever a compiler see a function, it just ignores the function. As MessageBox() is a function, the compiler will not do anything with it. All that the compiler will do is place an underscore before the name of the function, before placing it in the obj file as _MessageBox in the case of the program call2.c. After compiling the program call2.c, we may go to DOS, then to the directory c:\call2\debug. Here, we edit file call2.obj, and search for MessageBox. We can confirm that function MessageBox() is indeed present as _MessageBox. It is now the linker's job to find the code for this function. The linker will look through a series of files known as Lib files. These Lib files are nothing but a collection of obj files which contain the code of functions. In the first program, the linker doesn't find the code of _MessageBox in any of these lib files. This is why it comes back and gives us an error. In program call3.c, we find that on compiling, the function MessageBox() has not been placed in the obj file as _MessageBox, but as something else. Something whose code can be found by the linker, which is why we get no linker errors.
One thing that we notice is that the size of the file call3.exe is either the same as that of call1.exe or the difference in sizes is minor.
Let us attempt to unravel this mystery with the help of a simple function of our own, called abc().
call4.c:
int _stdcall WinMain(void *i,void *j,char *k,int l)
{
abc( );
}
The linker will inform us that it cannot find the code of _abc , which is why we get linker errors. Let us try to call the same function abc(), with one parameter, as shown below.
call5.c:
int _stdcall WinMain(void *i,void *j,char *k,int l)
{
abc(10 );
}
We didn't manage to call function abc() when the function had no parameters. We certainly didn't expect it to be called by just giving it a single parameter. The only reason why we added a parameter, was to see if a change in the error message had taken place. It hasn't. We still see 'unresolved external symbol _abc'. In fact, even if we try calling function abc() with ten parameters, we see the same error message.
call6.c:
int _stdcall WinMain(void *i,void *j,char *k,int l)
{
abc(10,20,30,40 );
}
In the next program, we have tried calling function abc() with four parameters. We see thsat the error message is still 'unresolved external symbol _abc'. This error message essentially means that the compiler has placed the name of function abc() as _abc in the obj file, irrespective of the number of parameters that the function has.
We think it is now time to introduce the concept of a 'calling convention'. All the above programs are 'C' programs, so by default, they all follow what is known as the 'C' Calling Convention. If any function in a 'C' program has to follow any other calling convention, this has to be explictly stated. Let us force function abc() to follow the Standard Calling Convention. We do this by having a prototype of function abc() before WinMain() as shown in the next program.
call7.c:
_ stdcall abc();
int _stdcall WinMain(void *i,void *j,char *k,int l)
{
abc( );
}
In the above program, we are calling a function abc() with no parameters. As compared to the previous programs, function abc() now follws the Standard Calling Convention. We see that this change in the way that the function abc() is called, results in the error message changing slightly. We now notice that the error message is 'unresolved external symbol _abc@0'. In other words, the name of function abc() that went into the obj file is no longer _abc, but instead, is _abc@0. Let's now call function abc() with a single parameter as we did in the program call4.c. We also rewrite the prototype of the function so the function abc() calls an int.
call8.c:
_ stdcall abc(int);
int _stdcall WinMain(void *i,void *j,char *k,int l)
{
abc( 10);
}
We see that the error message has once again changed. The linker has now come back and told us that it cannot find the code for _abc@4. Before we draw any conclusions from the significance of the Standard Calling Convention, let us call function abc() with four ints.
call9.c:
_ stdcall abc(int, int, int, int);
int _stdcall WinMain(void *i,void *j,char *k,int l)
{
abc( 10, 20, 30, 40);
}
We now see that the linker error is 'unresolved external symbol _abc@16'. If we go to DOS, change our directory to c:\call9\debug, and then say edit call9.obj, we shall see _abc@16 in this file.
Thus we see that each time we add an int to the parameters called by the function abc( ), the number at the end of the function name in the error message increases in multiples of 4. If we replace the four ints by four chars, we still see _abc@16 in the error message. That means that the type of parameters that the function is called with does not matter. As long as there are four parameters, function abc will appear in the obj file as _abc@16. This is because, under Windows95, every datatype occupies four memory locations. Sometimes, all these memory locations may not be used by the datatype. For example, in the case of a char, three memory locations are unused and wasted. In the standard calling convention, we can easily come to know the number of parameters that a function is called with, by looking at function name in the obj file.
Having obtained some amount of knowledge about Calling Conventions, it's time we got back to what we started out with, namely, the MessageBox. Take a good look at our program, especially at the function, MessageBox(0,"Hi","Bye",0). The prototype of this function will be MessageBox(int, char *, char *, int). If we had taken a look at the obj file when call3.c was compiled, we would have seen the name of function MessageBox() ending with @16. This gives us a clear indication that MessageBox uses the standard calling convention. This means that we now have to give the prototype of the function MessageBox(), specifying the calling convention that the function will follow. When function MessageBox() is called, it will now automatically follow the standard calling convention.
call10.c:
_stdcall MessageBox( int, char *, char *, int );
int _stdcall WinMain( void *i, void *j, char *k, int l )
{
MessageBox( 0, "Hi", "Bye", 0 );
}
To our surprise, we still get an error. Of course, the error message has now changed. The error message is 'unresolved external symbol _MessageBox@16'. Well, we used the standard calling convention, we passed the required number of parameters, so what went wrong ? Why couldn't the linker find the code for _MessageBox@16 ? Take a look once again at the file call3.obj. We shall find that the function MessageBox() is present as _MessageBoxA@16 and not as _MessageBox@16. Why do we have to add the additional 'A' ?
This is the time to bore you about marketing on a global scale, and such other things, things that are normally best left to people of lesser intellectual capabilities. Like MBAs, for instance. Anyway, ages ago, to enable computers to handle all the characters of the English language, ASCII was developed. However, the character set of the English language has only 26 capital letters, 26 small letters, 10 numbers, and a couple of punctuation marks. In other words, 8 bits or a byte which could have a mimum of 256 different combinations, was sufficient to handle the entire character set. But there were major markets in Asia, waiting to be tapped. Unfortunately, the language spoken in these countries was not English. Also, languages like Japanese and Chinese had character sets that were so large that they could not possibly be accomodated by a single byte, as in ASCII. Therefore, an alternative called UNICODE was developed to handle large character sets. UNICODE uses two bytes instead of one, to represent each letter of these language scripts. On the WindowsNT, UNICODE is used, while Windows95 uses good old ASCII.
Coming back to MessageBox, this is actually a macro. When we are using WindowsNT, MessageBox will be replaced by MessageBoxW to signify that UNICODE is being used, while under Windows95, MessageBox will be replaced be MessageBoxA to signify that ASCII is being followed. In effect, the inclusion of windows.h in the program call3.c results the macro MessageBox being replaced by MessageBoxA. The header file also specifies that the standard calling convention is being used. Therefore, the file call3.obj contains the term _ MessageBoxA@16. The linker knows where to find the code of _ MessageBoxA@16, which is why we didn't get any errors. All we have to do is replicate what the header file, windows.h, is doing.
call11.c:
_stdcall MessageBoxA(int, char *, char *, int);
int _stdcall WinMain( void *i, void *j, char *k, int l )
{
MessageBoxA(0,"Hi","Bye",0);
}
When we now compile this program, we encounter no problems, and get a MessageBox with "Hi" and "Bye", on execution.
Let us recount whatever we have learnt so far with the help of a simple example.
call.c:
#include<windows.h>
int _stdcall WinMain( void *i, void *j, char *k, int l )
{
aaa();
}
The first thing that we have seen is that the size of the exe file doesn't change considerably, with the addition of a function in the program. Secondly,a compiler doesn't look at functions. The compiler merely puts an underscore, that is a ' _ ' , before the name of the function and places _aaa in the obj file. The linker will look at a couple of Lib files to see if it can find the code of _aaa. These Lib files which the compiler looks at by default, are known as libc.lib and oldnames.lib. The linker will now come back with an error message informing us that it couldn't find the code of _aaa in any of these Lib files.
If we now include the prototype of the function aaa() by adding the line 'void _stdcall aaa();' , we are specifying that this function follows the standard calling convention. Now, function aaa() will go into the obj file as _aaa@0. Thus, we can safely say that the worst thing a compiler will do with a function, is change the name of the function, before placing it in the obj file. Beyond that, compilers have nothing to do with functions.
Dynamic Link Libraries
We move on to our next topic. We first click on New and create a Win-32 Dynamic Link Library project. Let us call our project dyn. Click on Ok, and once again select New. We give the name of the file as dyn.c.
dyn.c:
#include<windows.h>
void aaa()
{
MessageBox(0, "aaa", "Hi", 0);
}
When we compile and build this project, we do not see any exe file being created. Instead, a file called dyn.dll is created in the c:\dyn\debug directory. By now, some of you might have heard that the code of all functions in Windows95 is stored in DLLs. But we are actually looking our for more that a DLL from our project. Essentially, the aim of this project is to create a Lib file, and include it in the previous project call. We want that files in that project to be compiled, linked and executed without giving us any problems. As of now, call.c is giving us a linker error, saying that it can't find the code of the function aaa() in any of the default Lib files it looks into.
If we look at any of the dyn directory or it's Debug subdirectory, we find that there is no Lib file present. To obtain a file dyn.lib, we first have to create a Def file.
dyn.def:
LIBRARY dyn EXPORTS aaa
The first line of the Def file tell us the name of the Lib file that is going to be created when the project is executed. In the remaining part of the Def file, we have said that the file EXPORTS a function named aaa(). When we say EXPORTS, we mean that we are allowing everyone else to use whatever we have to export. And like all good Asians, we always export our best products, leaving the worst for the locals.
When we now compile and build our project, the linker will create a few additional files. We see a linker message saying ' Creating library Debug/dyn.lib and object Debug/dyn.exp '. Thus, we have created a .lib file and a .exp file. The size of dyn.dll doesn't change.
We may go back to our previous workspace, ie call. We click on Project, AddToProject, and select Files. In the EditBox, we type in c:\dyn\debug\dyn.lib. We have thus included the file dyn.lib into the workspace of call. When we compile and build call.c, it gives us no errors. This is because the linker has found the information it needed about function aaa() in the file dyn.lib.
However, on execution of the file call.exe, we get a very clear message. ' Could not execute. One of the library files needed to run this application could not be found '. This error message is definitely puzzling. We have, after all, already given the application the required Lib file. This means that we have to find out a little more about Lib files. If you look at the size of the Lib file, dyn.lib, you will notice that it is very small in comparison to the size of the DLL, dyn.dll. This is because all that the file dyn.lib contains, is information as to which DLL contains the code of the function aaa(). Didn't we tell you earlier that the code of a function is in a DLL ? However, Windows95 doesn't know that we have created a DLLs in the directory c:\dyn\debug. It only looks for DLLs in the windows\system directory. Since it doesn't find dyn.dll in windows\system, we get a run-time error. To eliminate this error, all that we have to do, is copy dyn.dll into the windows\system directory. When we execute call.exe, we now get a message box, confirming that the function aaa() was executed.
Let's add another function into program dyn.c, called bbb( ).
dyn.c:
#include<windows.h>
void aaa()
{
MessageBox(0,"aaa","Hi",0);
}
void bbb()
{
MessageBox(0,"bbb","Bye",0);
}
As before, we copy the dyn.dll into windows\system. We also modify the program call.c, so that in addition to function aaa(), function bbb() is also be called.
call.c:
#include<windows.h>
int _stdcall WinMain( void *i, void *j, char *k, int l )
{
aaa();
bbb();
}
Now, when we compile and build program call.c, we get a linker error. One that has, over the last couple of pages, been repeated so frequently, that we might err in thinking that it is a popular request on MTV Most Wanted ! ' Unresolved external symbol ...'. We seen it so many times, and they still keep repeating it.
But why, we ask ourselves, does the addition of one more function cause these problems. We were probably so disgusted on seeing the linker error, that we didn't even take a close look at what it had to say. Because if we did, we would see that nowhere in the error message, is there any mention of the function aaa(). All that the linker says, is that it can't find the code of function bbb().
And then it strikes us. How could we be so silly? We didn't state that function bbb is to be exported, in the Def file. How then, can anyone access this function? No wonder, we got an error! We now modify our Def file as shown below.
dyn.def:
LIBRARY dyn EXPORTS aaa EXPORTS bbb
We now recompile and build dyn.c. We also copy the new DLL created into windows\system. Now, we have no problems with this program, and on execution, we see two message boxes, one after the other, on our screen.
What happens if, in program dyn.c, function aaa() follows the standard calling convention?
dyn.c:
#include<windows.h>
void _stdcall aaa()
{
MessageBox(0, "aaa", "Hi", 0);
}
void bbb()
{
MessageBox(0,"bbb","Bye",0);
}
If that was the case, the prototype of the function aaa(), specifying that this function follows the standard calling convention, would have to be added into our program. Otherwise, we shall get our all too familiar error message, 'unresolved external symbol _aaa'. Obviously, the linker is searching for _abc, when it should be searching for _abc@0. The modified program call.c is as shown below.
call.c:
#include<windows.h>
void _stdcall aaa();
int _stdcall WinMain( void *i, void *j, char *k, int l )
{
aaa();
bbb();
}
The above program executes without giving us any headaches. But what if file call.c had been a .cpp file? One definite difference is that we are forced to have a prototype for both the functions, otherwise we shall get compiler errors.
call.cpp:
#include<windows.h>
void _stdcall aaa();
void bbb();
int _stdcall WinMain( void *i, void *j, char *k, int l )
{
aaa();
bbb();
}
This time, we get linker error messages for both the functions, aaa() and bbb(). Certain problems arise when we have functions in a C++ file. One reason for these difficulties, is that C++ introduces name mangling in the function names that go into the obj file. This problem will be solved if the code of both the functions are in a .Cpp file. By this, we mean that instead of dyn.c, we have dyn.cpp. Now, whatever name mangling that has been introduced in one C++ file, will also be present in the other C++ file, and when we execute call.exe, we shall get no errors.
But what would have happened if we wanted to call a function whose code is present in a DLL that has already been created by compiling and linking a .C file? For example, take a case where the code of functions aaa() and bbb() were originally written in file dyn.c. Let us assume that we do not have the original .C file available with us, and all that we have is a DLL, dyn.dll. Also assume that we have to call these functions from call.cpp. In such a case, we are forced to find a way to tell the C++ compiler not to introduce name mangling while calling these functions as they originate in a .C file. This is done by placing extern "C" in front of the prototypes of both the functions as shown below.
call.cpp:
#include<windows.h>
extern "C" void _stdcall aaa();
extern "C" void bbb();
int _stdcall WinMain( void *i, void *j, char *k, int l )
{
aaa();
bbb();
}
When function aaa() and bbb() are called, the C++ compiler makes sure that there is no name mangling of function names. The program now executes without problems.